










Servicios Personalizados
Revista
Articulo
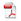 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkNúcleo
versión impresa ISSN 0798-9784
Núcleo v.22 n.27 Caracas dic. 2010
Estudio comparativo de traductores automáticos en línea: Systran, reverso y google
Mariana González Boluda
University of Technology, Jam ica Department of Liberal Studies Faculty of Education and Liberal Studies 237, Old Hope Road, Kingston 6 (Jamaica) Telf.: (1 876) 850 94 23 mgonzalez@utech.edu.jm
Es Licenciada en Filología Hispánica por la Universidad de Murcia (España).Tiene un Máster en Enseñanza yAprendizajeAbiertos y a Distancia de la Universidad Nacional de Educación a Distancia (UNED), España. Actualmente es doctoranda del Departamento de Filologías Extranjeras de la UNED. Fue lectora de español de la Agencia Española de Cooperación Internacional (AECI) en la University of the West Indies de Jamaica de 1996 a 2000 y posteriormente continuó como profesora de español en el Departamento de Lenguas Modernas de la misma universidad. Actualmente es profesora de español y coordinadora de los programas de Español delTurismo del Departamento de Estudios Liberales de la University ofTechnology, Jamaica. Sus áreas de investigación incluyen la adquisición de lenguas extranjeras, el uso de la traducción automática como herramienta de aprendizaje de lenguas y el desarrollo de la autonomía en el aprendizaje de lenguas a través del uso de herramientas de la Web 2.0 (blogs, wikis y redes sociales).
RESUMEN
Como consecuencia de la globalización existe una necesidad cada vez mayor de acceder a más información. La traducción automática puede satisfacer las necesidades de un gran número de usuarios potenciales a través de numerosos programas disponibles en Internet. Teniendo en cuenta el creciente desarrollo de estos programas de traducción automática disponibles en línea, es fundamental conocer cómo funcionan y evaluar sus resultados con el fin de sacarles el mejor provecho posible y conocer sus limitaciones y su potencial. En este estudio se hace una evaluación de tres programas de traducción automática disponibles en Internet: Systran, Reverso y Google. Se presentan las principales dificultades con las que se enfrenta cada uno de estos sistemas de traducción automática a través de un análisis de traducciones de oraciones y frases breves del inglés al español; se analizan los problemas y se determina cuál de los tres traductores automáticos usados obtiene mejores resultados.
Palabras clave: traducción automática, evaluación de la traducción automática, análisis lingüístico de traductores automáticos inglés-español.
Comparative Study of Online Translators: Systran, Reverso, and Google
ABSTRACT
As a result of globalization, there is a growing need to access more information. Machine translation, as an instrument of mass translation to meet the needs of a greater number of potential users, has been enhanced by the emergence and development of numerous online translator programs. Given their increasing presence, especially on the Internet, it is essential to evaluate the performance of these machine translation systems and to determine their limitations and potential. What we propose with this study is to evaluate three machine translation systems available online, Systran, Reverso and Google. We will present the main difficulties posed by machine translation through an analysis of translations of brief English sentences and phrases into Spanish. Our study will analyze the problems that appear and determine which of the three online translators gave the best results.
Key words: machine translation, machine translation evaluation, linguistic analysis for English Spanish machine translators.
Étude comparative de traducteurs automatiques en ligne : Systran, Reverso et Google
RÉSUMÉ
La mondialisation entraîne un besoin croissant daccès à linformation. La traduction automatique pourrait satisfaire les besoins dun grand nombre dusagers potentiels à laide de nombreux logiciels disponibles sur Internet.Vu que le développement de ces logiciels de traduction automatique sur Internet a augmenté, il est nécessaire de connaître leur fonctionnement et dévaluer leurs résultats afin den profiter le mieux possible,ainsi que de connaître leurs limitations et leur potentiel.Cette étude porte sur une évaluation de trois logiciels de traductions disponibles sur Internet : Systran, Reverso et Google. Lon présente les problèmes les plus importants liés à ces systèmes de traduction automatique au moyen dune analyse de la traduction de phrases et dénoncés brefs de langlais vers lespagnol, ainsi quune évaluation de ces problèmes. Finalement, létude montre le traducteur automatique employé qui remporte les meilleurs résultats.
Mots clés: traduction automatique, évaluation de la traduction automatique, analyse linguistique de traducteurs automatiques anglais espagnol.
Estudo comparativo de tradutores automáticos online: Systran, Reverso e Google
RESUMO
Como consequência da globalização existe uma necessidade cada vez maior de acessar a mais informação.A tradução automática pode satisfazer as necessidades de um grande número de potenciais usuários através de numerosos programas disponíveis na Internet. Considerando o crescente desenvolvimento destes programas de tradução automática disponíveis online, é essencial conhecer como funcionam e avaliar seus resultados a fim de tirar o maior proveito deles, bem como conhecer suas limitações e seu potencial. Neste estudo se faz a avaliação de três programas de tradução automática disponíveis na Internet: Systran, Reverso e Google. Apresentamse as principais dificuldades de cada um desses sistemas de tradução automática obtidas através da análise de traduções de orações e frases breves do inglês ao espanhol, analisamse os problemas e se determina qual dos três tradutores automáticos estudados oferece melhores resultados.
Palavras chave: tradução automática, avaliação da tradução automática, análise linguística de tradutores automáticos inglês espanhol.
Recibido: 29/06/10 Aceptado: 21/12/10
1. INTRODUCCIÓN
Nadie pone en duda en estos momentos que la tecnología y las herramientas informáticas desempeñan un papel esencial en el trabajo del traductor en términos de calidad y productividad. Sin embargo, la traducción automática sigue suscitando al mismo tiempo muchos recelos por parte de traductores profesionales, entre los que podemos encontrar todo tipo de opiniones a favor y en contra.
La traducción automática está mejorando; en los últimos años ha habido muchos avances y no dudamos que estos sistemas de traducción ayudan de una manera muy importante a mucha gente, permitiéndole el acceso a una gran cantidad de información que no aparece en su lengua. Como señala Bel (2001), hoy en día, y cualquiera puede comprobarlo gratis en Internet, la traducción automática es una aplicación real que está siendo utilizada1. Un gran número de usuarios de Internet utiliza estos sistemas de traducción automática, así como muchas organizaciones internacionales que los usan en la traducción de determinados textos, como por ejemplo la Unión Europea (UE), que utiliza el sistema Systran, o la Organización Panamericana de la Salud (PAHO, por sus siglas en inglés [Pan American Health Organization]), que tiene su propio sistema de traducción automática, SPANAM & ENGSPAN. Así pues, teniendo en cuenta su presencia cada vez mayor, sobre todo en Internet, es fundamental conocer cómo funcionan estos sistemas de traducción automática disponibles en línea y evaluar sus resultados con el fin de sacarles el mejor provecho posible y conocer sus limitaciones y su potencial.
Siguiendo a López (2002), hablamos de una tecnología ciertamente muy avanzada pero que trabaja con la lengua y su complejidad. Como señala Hernández (2002: 107), para un traductor automático es difícil hacerse cargo de las ambigüedades del lenguaje. De acuerdo con Arnold et al. (1994: 35)2, un traductor humano usa por lo menos cinco tipos de conocimiento de la lengua de origen, de la lengua meta, de los equivalentes entre la lengua de origen y la lengua meta, del campo de especialidad y conocimiento general de la lengua de origen y la lengua meta, de los aspectos socioculturales, entre los que se encuentra el conocimiento pragmático y del mundo, es decir, de las costumbres y convenciones de las culturas de origen y meta. La carencia de este conocimiento del mundo representa uno de los límites de esta tecnología. Por lo tanto, tendremos que estar conscientes de que estos sistemas pueden ser muy útiles para determinadas aplicaciones y áreas específicas, pero no para todas.
La traducción automática puede desempeñar un papel muy importante a la hora de traducir textos técnicos que, por su precisión y características semánticas, sintácticas y estilísticas, son los más apropiados para obtener una traducción automática aceptable. Según López (2002), cada vez más los sistemas de traducción automática se basan en sublenguajes o lenguajes de especialidad, como el lenguaje médico, el jurídico, el científico, donde se pueden obtener los mejores resultados.
El objetivo principal que nos proponemos con este trabajo es hacer una evaluación de tres programas de traducción automática disponibles en Internet. Primero haremos una breve descripción de su funcionamiento y presentaremos una reflexión sobre la dificultad de evaluar este tipo de programas, así como los parámetros que deberíamos tener en cuenta para realizar esta evaluación. Luego pasaremos a enumerar los principales problemas a los que se enfrenta un sistema de traducción automática y realizaremos un análisis de traducción con oraciones y frases de prueba del inglés al español.
Nuestro objetivo final es analizar los problemas a medida que van surgiendo y ver qué programa de traducción automática obtiene mejores resultados. En el último apartado expondremos nuestras conclusiones sobre los resultados de la evaluación de estos tres programas de traducción.
2. MARCO TEÓRICO
Teniendo en cuenta todos los avances que han tenido lugar en los últimos años y toda la literatura estudiada sobre traducción automática, podemos afirmar que este tipo de traducción ayuda a un gran número de usuarios, al mismo tiempo que puede aportar muchísimo al trabajo del traductor moderno (Diéguez y Riedemann, 1998). La traducción automática es una de las aplicaciones más ambiciosas de la lingüística computacional, en el sentido de que trata de reproducir la capacidad humana de procesar el lenguaje (Grishman, 1991). En un sistema de traducción automática, un texto de una lengua fuente es procesado hasta lograr un nivel de comprensión suficiente. Tradicionalmente, las aproximaciones usadas para el tratamiento de la lengua se han basado en el conocimiento lingüístico (fonológico, morfológico, sintáctico, semántico). Sin embargo, Los sistemas de traducción automática se clasifican según la estrategia de análisis que utilicen. En este sentido, y de acuerdo con Hutchins (2001), hay sistemas basados en reglas (sistemas de traducción directa, de interlingua, de transferencia), sistemas basados en corpus (sistemas estadísticos y aquellos basados en ejemplos) y sistemas híbridos.
Los sistemas de traducción directa están diseñados para un par de lenguas en particular. Parten de la idea de que el vocabulario y la sintaxis de los textos de la lengua fuente solo se analizan en lo más estrictamente necesario para resolver ambigüedades e identificar las expresiones apropiadas y el orden de las palabras de la lengua meta. Según Valdés (1989), este enfoque fue utilizado en los sistemas de traducción automática de los años 50 y 60 y el producto típico de esta estrategia fue el diccionario de traducción (Translation Dictionary). Estos sistemas de traducción recurren básicamente a léxicos monolingües y bilingües. Pueden traducir grandes volúmenes de documentos en poco tiempo pero, puesto que traducen casi palabra por palabra, sin haber analizado antes la frase entera o sin haberla entendido en su totalidad, generan traducciones de baja calidad. Son aceptables si el usuario valora más la rapidez con la que nos proporcionan una idea general que la propia calidad del texto. Tal como señala López (2002), aunque son muy rápidos... la calidad de la traducción que ofrecen es muy baja.
En los sistemas de traducción de interlingua, se asume que es posible convertir un texto de la lengua fuente en representaciones sintácticosemánticas comunes para más de una lengua; se argumenta a su favor, en el sentido de los efectos de economía, que se puede traducir con un solo sistema a varias lenguas. Según Llisterri (2009),
un traductor automático basado en la interlengua proporciona buenos resultados con textos de un ámbito muy restringido, pero presenta aún problemas importantes tanto en el diseño como en la puesta en práctica. La principal dificultad estriba en la representación exhaustiva de los conceptos en términos de rasgos semánticos y de las relaciones que pueden establecerse entre ellos.
En los sistemas de traducción de transferencia, la traducción se realiza en tres fases: análisis, transferencia y generación. La primera etapa consiste en la conversión de los textos de la lengua fuente en representaciones de transferencia de la misma lengua fuente. La transferencia puede realizarse tanto a nivel léxico como sintáctico y semántico. Es decir, se traducen las palabras de una lengua a otra teniendo en cuenta las condiciones del contexto morfológico, sintáctico y semántico de la frase.
Al mismo tiempo, se lleva a cabo la transferencia estructural o los cambios en el orden de elementos y en la estructura de la frase. Finalmente, existe una fase de generación en la cual se obtiene la frase final traducida. En palabras de López (2002), estos sistemas de transferencia contienen además de grandes léxicos monolingües y bilingües, un amplio conocimiento sintácticosemántico de las lenguas tratadas.
Estos enfoques forman parte de los sistemas de traducción automática basados en reglas. Según López (2002), hay que tener en cuenta que no hay sistemas puros de traducción directa, de transferencia o de interlingua sino sistemas que se aproximan más a un enfoque determinado, pero que pueden tener características de uno de los otros. Estos sistemas de transferencia e interlingua han puesto de manifiesto que su elaboración es lenta y requiere una gran inversión intelectual y tecnológica. Por ello, se han creado sistemas basados en ejemplos y estadísticos, que disponen de un corpus de documentos ya traducido; suelen funcionar si se trata de documentos rígidos con un lenguaje controlado (Oliver, More y Climent, 2008: 2126). Obviamente, si comparamos todos estos sistemas de traducción automática desde que empezaron a desarrollarse en los años 50, veremos que el diseño de los distintos programas ha mejorado (López, 2002).
Además del diseño de los sistemas, en este estudio también tendremos en cuenta otros criterios, tales como el número de lenguas que traducen así como los resultados obtenidos al momento de traducir oraciones breves del inglés al español. No pretendemos abarcar aquí todos los temas relacionados con la evaluación de la traducción automática sino que hemos decidido reducir el objeto de la investigación al ámbito de la evaluación lingüística del producto de la traducción automática. Esto significa que no vamos a describir ni evaluar los componentes internos del programa; se trata de una evaluación de la caja negra, en palabras de Hutchins y Somers (1995: 49), en la que solo observaremos los resultados del proceso de traducción automática.
3. MARCO METODOLÓGICO
Para realizar este estudio comparativo hemos utilizado diferentes tipos de frases y oraciones originales en inglés donde creíamos que habría dificultades para los programas de traducción automática, con el fin de analizar los resultados y formular hipótesis sobre sus errores y aciertos. En las frases y oraciones que hemos seleccionado hay casos de ambigüedad léxica (polisemia, homonimia), calcos léxicos y sintácticos, construcciones pasivas, refranes, modismos, locuciones, colocaciones, siglas y nombres propios.
En cuanto a los programas de traducción automática usados en esta investigación, se trata de tres programas disponibles en línea, Google, Systran y Reverso, los cuales pueden ser consultados de manera gratuita por cualquier usuario en Internet.
3.1 Descripción de los programas de traducción automática
Hay un gran número de programas de traducción en línea que se pueden consultar de manera gratuita. Para este estudio hemos seleccionado tres de ellos: Systran, Reverso y Google. Estos programas se hicieron con la finalidad de reducir la barrera del idioma que afecta a muchísimas personas que consultan diariamente Internet. De acuerdo con información suministrada por Diéguez y Lazo en el año 2004 (2004: 61), para ese momento más del 60% de las páginas Web estaban diseñadas en inglés, según estimaciones de la compañía de análisis informático Global Reach, pero un porcentaje mucho menor de usuarios de Internet hablaba ese idioma.
La mayoría de estos programas tiene muy buenos resultados si lo que se quiere es tener una idea general del texto original; su funcionamiento mejora con lenguajes especializados por el uso de frases breves y por la repetición de estructuras léxicas y gramaticales. Todo dependerá del propósito de la traducción, de las necesidades del usuario y del tipo de texto que se vaya a traducir.
Estos programas disponibles en línea no tienen que descargarse ni instalarse en el ordenador; el usuario solamente tiene que acceder al sitio del programa para traducir lo que necesite. Normalmente hay una ventana donde se pega o se escribe el texto que se quiera traducir; después se elige el idioma al que se desea traducir el texto y en tan solo unos segundos aparece la traducción en la pantalla. Como se puede ver, la rapidez y la facilidad de manejo son algunas de sus ventajas, además de que son gratuitos. McElhaney y Vasconcellos (1988) señalan también entre sus ventajas la consistencia a la hora de procesar unidades léxicas y terminológicas.
3.2 Parámetros de evaluación
Estamos de acuerdo con la afirmación de Arnold et al. sobre la dificultad de evaluar los sistemas de traducción automática: La evaluación de los sistemas de traducción automática es una tarea compleja, no solo por la variedad de factores implicados sino porque medir el resultado de la traducción en sí mismo es una tarea difícil (1994: 165166). Cerezo (2003: 158159) expone algunas de las razones de la dificultad a la hora de evaluar la traducción humana o automática, entre las que destaca el hecho de que la traducción puede entenderse como proceso o como producto. Cerezo destaca la complejidad tanto del proceso como del producto: el proceso implica una serie de tareas que no son siempre las mismas y el producto varía según los factores que intervengan en el proceso.
Con respecto a los parámetros que han sido más estudiados al evaluar estos programas de traducción automática, Diéguez y Cabrera (1996) mencionan el tiempo, el costo y la calidad.
1) Tiempo: se ha demostrado que estos programas pueden ayudar al traductor a rendir más en menos tiempo.
2) Costo: son muchos los aspectos que deben tenerse en cuenta, tales como la inversión inicial, el mantenimiento del sistema, la constante actualización, la alimentación de glosarios y el trabajo de postedición (Vasconcellos, 1988).
3) Calidad: según Diéguez y Cabrera (1996), hay que considerar variables tales como la cantidad y grado de confiabilidad de la información terminológica que el programa contenga.
A estos tres parámetros, Diéguez y Cabrera (1996) añaden otras dos variables, como son el área temática y el tipo de texto, que deben considerarse también cuando se evalúan estos sistemas de traducción automática.
4) El área temática va a afectar los resultados de estos programas. La calidad aumentará en la medida en que el programa que utilicemos cuente o no con glosarios especializados en diferentes áreas temáticas.
5) El tipo de texto que estemos traduciendo va a ser de gran relevancia a la hora de tomar decisiones sobre la calidad de estos programas. Dependiendo del tipo de texto que usemos (periodístico, técnico, literario, entre otros), obtendremos diferentes resultados. El análisis de traducción realizado por Diéguez y Cabrera (1998) demuestra que se presenta una serie de problemas recurrentes de distinta naturaleza según el tipo de texto traducido.
En nuestro trabajo hemos considerado los siguientes parámetros de evaluación:
1) Número de lenguas que traducen Systran, Reverso y Google.
2) Enfoque de traducción.
3) Análisis de traducción de frases y oraciones breves del inglés al español.
4. EVALUACIÓN DE LOS TRADUCTORES AUTOMÁTICOS SYSTRAN, REVERSO Y GOOGLE
4.1 Número de lenguas
Si comparamos el número de lenguas que traducen los tres programas, Google ofrece más ventajas ya que traduce prácticamente en todos los idiomas (en este momento ofrece traducciones en 52 lenguas). Si lo comparamos con Systran, que traduce 13 lenguas al inglés y viceversa y de seis idiomas al francés y viceversa, o con Reverso, que nos permite traducir siete lenguas al inglés y viceversa y de tres idiomas al francés y viceversa, vemos que Google ofrece posibilidades de traducir un número mucho mayor de lenguas y que, además, no restringe su uso a opciones predeterminadas como, por ejemplo, al inglés o al francés, como ocurre con Systran y Reverso, sino que permite elegir cualquier lengua (por ejemplo, traducir del árabe al sueco) sin ningún tipo de restricciones.
4.2 Enfoque de traducción
Los sistemas de traducción automática utilizados por cada uno de los tres programas son los siguientes:
● Systran usa un sistema directo, es decir, para cada palabra de la lengua de origen hay un equivalente en la lengua meta. Los diccionarios y los mecanismos para el análisis morfológico son muy completos pero los procesos de análisis sintáctico son bastante limitados.
● Reverso utiliza sistemas de transferencia en los que podemos distinguir tres etapas en su funcionamiento. Tal como señalan Diéguez y Riedemann (1998: 214215), en la primera fase se analiza el texto fuente en la lengua original a nivel morfológico, sintáctico y semántico. En la fase de transferencia se transforma esa estructura a la que llegamos en la fase anterior a otra estructura similar en la lengua meta. En la última fase se genera la oración en la lengua meta.
● Los sistemas de traducción automática estadística, como el desarrollado por Google, generan traducciones a partir de métodos estadísticos basados en corpus de textos bilingües. Primero se alinean las oraciones de los textos de la lengua de origen y la lengua meta y después se calculan las probabilidades de traducción o de equivalencia, es decir, las probabilidades de que se correspondan con otras de traducciones realizadas por profesionales en ambas lenguas.
En cuanto a qué sistema es mejor, compartimos la opinión de Moreno (2000) quien afirma que no hay un enfoque definitivo que solucione todos los problemas y dificultades de la traducción automática. Normalmente los sistemas que tienen más éxito son los que integran técnicas de diferentes enfoques, es decir, los híbridos, que adoptan una postura ecléctica.
4.3 Análisis de traducción de frases y oraciones breves
Seguidamente vamos a traducir oraciones y frases donde creemos que habrá algunas dificultades para el traductor automático con el propósito de analizar las respuestas dadas y formular hipótesis sobre sus limitaciones y aciertos. En las oraciones y frases seleccionadas aparecen fenómenos lingüísticos bastante comunes de ambigüedad léxica (polisemia, homonimia), calcos léxicos y sintácticos, construcciones pasivas, refranes, modismos, locuciones, colocaciones, siglas y nombres propios. Se ha intentado comprobar si los tres traductores automáticos seleccionados son capaces de identificar estos fenómenos y luego encontrar una traducción sin que esta sea una traducción literal.
Como no es fácil generalizar al evaluar todos los programas de traducción, puesto que, como veremos en los ejemplos que siguen, los mismos programas ofrecen mejores o peores resultados dentro de cada aspecto lingüístico analizado, haremos comentarios de cada uno de los fenómenos lingüísticos presentados uno por uno, con el fin de hacer más fácil la comparación.
Ambigüedad léxica: homonimia y polisemia
La homonimia consiste en la identidad fónica entre dos o más palabras que se pronuncian de la misma manera pero poseen significados distintos; su ortografía puede ser diferente (Cardona, 1991). La traducción de los ejemplos dados de homonimia ha dado algunos problemas a los traductores automáticos. Lo mismo ha ocurrido en los casos de polisemia, en los que un solo significante tiene dos o más significados (Cardona, 1991), y donde los traductores automáticos también han encontrado algunas dificultades. Pero, ¿cómo pueden Systran, Reverso y Google saber qué significado tienen que elegir? Obviamente a través del contexto, pero esto no resulta tan fácil porque necesitarían mejorar sus diccionarios, gramáticas y correlaciones estadísticas. En los casos analizados, los tres traductores automáticos no tienen todas las acepciones o en otros casos sí las tienen pero no tienen la capacidad de reconocer la acepción correcta según el contexto, por lo que las traducciones dadas no son correctas. En el ejemplo número 1 (ver cuadro 1), ninguno de los traductores automáticos ha resuelto todos los casos de ambigüedad léxica. Reverso ofrece todas las acepciones de los términos pero no sabe cuál elegir, Systran elige la acepción correcta en uno de los ejemplos, Google elige la acepción incorrecta. En los ejemplos número 2 y 4, Google identifica dos de las acepciones de los términos usados con mejores resultados que Systran y Reverso, y en el ejemplo número 3, los tres traductores eligen la primera acepción correcta del término, pero ninguno de ellos encuentra la segunda acepción.
Calcos léxicos y sintácticos
En el calco léxico se adopta un significado de la lengua fuente, en nuestro caso del inglés, para una palabra existente en la lengua meta (Diccionario de la Lengua Española, DRAE). En el ejemplo número 5 (ver cuadro 2), la solución dada por dos de los traductores automáticos, endosar en lugar de apoyar, es un calco léxico del inglés to endorse. Solamente Google ha solucionado el problema y ha elegido la acepción adecuada para el contexto: apoyar. La razón por la que los otros programas no han acertado puede deberse a un lexicón pobre (puede haber sido el caso de Systran que ha elegido la acepción incorrecta endosar) o porque quizás no han podido reconocer el contexto, lo que les ha impedido elegir la acepción más adecuada, como puede haber sido el caso del programa Reverso, que lo traduce como endosar y aprobar.

El calco sintáctico en el orden oracional se da cuando se usa una estructura típica de la lengua fuente que también tiene la lengua meta pero con restricciones. Por ejemplo, el orden oracional típico en inglés responde a sujeto + verbo + objeto, igual que en español, pero en algunos casos en español se puede hacer énfasis en el verbo y cambiar la estructura a verbo + sujeto, como muestra el ejemplo número 6, Si te llama tu jefe. Como muy bien señala García González (1998: 600), el orden oracional del inglés es bastante rígido mientras que el español también sigue este orden básico pero se caracteriza por una mayor libertad constructiva y la facilidad con que se pueden invertir los elementos de la oración.Así como ocurre en este ejemplo, se produce la inversión verbo + sujeto pero ninguno de los traductores automáticos ha captado este énfasis que se hace en el verbo y ha mantenido el orden oracional típico, sujeto + verbo. A pesar de mantener este orden oracional, la traducción obtenida es válida y se entiende sin afectar el sentido de la cláusula.
En el ejemplo número 7, the entire day..., vemos cómo la posición del adjetivo en inglés también difiere si la comparamos con el español. En inglés los adjetivos se colocan delante del sustantivo; sin embargo, en español el adjetivo va detrás del sustantivo, aunque hay algunos casos en los que se antepone pero entonces cambia su valor expresivo. En este caso no ha habido ningún problema en la traducción ya que los traductores reconocen este orden oracional en español, como podemos ver en los resultados de este ejemplo número 7: se han obtenido traducciones correctas con los tres traductores usados.
Calcos sintácticos en los sintagmas verbal, nominal y preposicional. Son frecuentes los calcos sintácticos por parte de los traductores automáticos de la misma estructura de los sintagmas verbales, nominales y preposicionales de la lengua fuente, como se observa en los ejemplos número 8, mira para ser, número 9, tomarse su tiempo, y número 10, tomar conmigo: se mantiene la misma estructura del sintagma verbal de la lengua de origen (mira para ser, ejemplo 8), se continúan usando posesivos en casos donde el español no los usa (su tiempo, ejemplo 9) y se mantiene el sintagma preposicional (tomar conmigo, ejemplo 10) en casos que no son frecuentes en español. Solamente en el ejemplo número 8 se ofrecen traducciones en las que la frase pierde sentido, exceptuando la dada por el traductor de Google. En la traducción de Systran del ejemplo 9, se elige la acepción errónea, pero en el resto de los ejemplos las traducciones ofrecidas por los programas se entienden bastante bien, aunque se calquen estructuras que no son frecuentes en español en algunos casos.
En este apartado sobre calcos léxicos y sintácticos,hemos visto que aunque se haya optado por una acepción poco adecuada o no se respetara el orden sintáctico normal del español, en la traducción ofrecida en la mayoría de los casos por los traductores automáticos no se ha alterado mucho el sentido de las oraciones. Solamente en el ejemplo número 8, en la traducción hecha por Systran y Reverso, sí se ha alterado el sentido de la oración, debido a que se ha traducido literalmente la expresión verbal looks to be, palabra por palabra.
Construcciones pasivas
Como se verá, en la traducción de construcciones pasivas hay algunos errores que no impiden la comprensión global del mensaje (ver cuadro 3). El inglés emplea más la voz pasiva que el español; normalmente se usa en español cuando interesa más señalar lo sucedido al sujeto paciente que indicar el agente o autor de dicha acción, bien porque sea desconocido o no se quiera nombrar (García González, 19971998: 609). Solamente en uno de nuestros ejemplos puede aceptarse el uso de la voz pasiva (Fue expulsado por el director de la escuela), pero en el resto de los casos el uso de la voz pasiva es incorrecto. Systran (en tres de los ejemplos) y Google (en todos los ejemplos) resuelven el problema de la traducción de la voz pasiva mientras que Reverso emplea la voz pasiva en todos los ejemplos. No obstante, como mencionamos al principio, estas incorrecciones no afectan el sentido de la oración, excepto en el ejemplo número 14, A lot of money was spent, donde se pierde el sentido original debido a la ambigüedad léxica del verbo spend, para el que existen varias traducciones posibles en función del contexto. Systran ha elegido la acepción errónea y ha cambiado totalmente el significado del original. Reverso, en este caso, lo ha traducido con sus dos acepciones (gastado y pasado) para que el usuario elija aquella que crea correcta.

Refranes y modismos
Los refranes y modismos o expresiones idiomáticas son bastante difíciles de traducir; de hecho, los traductores automáticos no los reconocen en la mayoría de los casos propuestos, ya que la traducción no se puede obtener al traducir palabra por palabra. En el caso de los refranes usados para nuestro análisis (ver cuadro 4), solamente en uno de ellos el número 22, A bird in the hand is worth two in the bush el referente designado en la lengua de origen equivale parcialmente al de la lengua meta, por lo que resulta más fácil conseguir una traducción correcta, y así ha sido ya que dos de los traductores automáticos elegidos, Google y Reverso, lo han traducido correctamente.
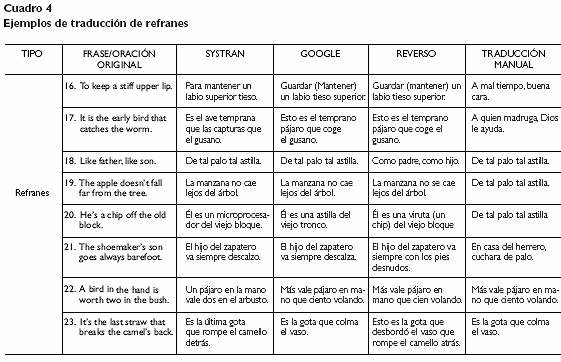
En el resto de los ejemplos con refranes no hay ninguna equivalencia con la lengua meta,por lo que exigen una adaptación por parte de los traductores.En este caso, a pesar de las dificultades en dos de ellos el número 18, Like father, like son y el número 23, Its the last straw that breaks the camels back, se han conseguido traducciones correctas con Systran y Google en el ejemplo número 18 y con Google en el ejemplo número 23.
En la traducción de modismos los resultados han sido peores (ver cuadro 5); solamente se ha conseguido una traducción correcta en dos de los ejemplos: el número 24, Add fuel to the fire, y el número 29, As straight as a die. En estos dos casos, Google y Reverso han traducido correctamente el ejemplo número 24 y solo Reverso ha traducido correctamente el número 29.

Para resumir, en estos ejemplos concretos se observa que Google ha conseguido mejores resultados en tres de los refranes traducidos, mientras que en la traducción de modismos ha sido Reverso el que ha tenido mejores resultados al traducir correctamente dos.
Locuciones
En cuanto a la traducción de locuciones adverbiales o grupos de palabras que equivalen a un solo adverbio, también hemos encontrado algunas dificultades (ver cuadro 6). Systran, Google y Reverso han traducido de forma correcta la mitad de los ejemplos dados; en el resto de los ejemplos, los programas nos han dado una traducción literal, traduciendo palabra por palabra.

Colocaciones
Siguiendo la definición dada por Corpas Pastor, las colocaciones son
unidades fraseológicas que, desde el punto de vista del sistema de la lengua, son sintagmas completamente libres, generados a partir de reglas, pero que, al mismo tiempo, presentan cierto grado de restricción combinatoria determinada por el uso (cierta fijación interna) (1996: 53).
En su traducción se han producido algunos errores; Google ha dado una traducción correcta de todos los ejemplos (ver cuadro 7), mientras que Systran y Reverso han traducido de forma inadecuada tres de ellos, es decir que no han reconocido la combinación fija de palabras y las han traducido literalmente.

Siglas
La traducción de siglas no ha presentado problemas (cuadro 8). No se ha traducido el ejemplo número 42 (CARICOM) probablemente porque mantiene las siglas en inglés, aunque sí tiene traducción en español. En algunos casos no siempre lo que se indica en siglas en una lengua se traduce en otra; algunas veces se mantiene la forma original, sobre todo cuando se trata de siglas de difusión general, como es el caso de UNESCO (United Nations Educational, Scientific and Cultural Organization) y CDROM (Compact Disc Read Only Memory), o cuando hay dificultades para traducirlas. Los traductores automáticos recogen las siglas más comunes.

Nombres propios y topónimos
Con los ejemplos analizados vemos que algunos de los traductores automáticos también incluyen nombres propios y topónimos. Systran los ha traducido (cuadro 9) pero al invertir el orden de colocación, la traducción resultante no tiene sentido (Blanco de Juan, Carpintero de María). Reverso los ha traducido todos correctamente y ha dejado uno sin traducir (John White). Google no ha traducido ninguno de los nombres propios. Antes se traducían casi todos los nombres de persona o antropónimos, ahora se mantiene la opinión de que deben conservarse. Lyons (1980: 210) comenta la complejidad a la hora de traducir los nombres personales: La traducción de nombres personales es todavía más compleja, ya que, aunque exista un equivalente bien establecido, no siempre parece adecuado utilizarlo.

En la traducción de topónimos (cuadro 10), Systran no ha traducido el ejemplo número 47 (Cape Town), probablemente porque no lo ha reconocido, mientras que sí ha traducido sin problemas el resto. Google y Reverso no han tenido ningún problema en conseguir una traducción correcta de los topónimos.

5. CONCLUSIONES
En el análisis lingüístico de traducciones de frases y oraciones, podemos decir que el traductor Google, si lo comparamos con Systran y Reverso, ha tenido mejores resultados en los casos de ambigüedad léxica, calcos léxicos y sintácticos, construcciones pasivas y colocaciones. En refranes y modismos, locuciones adverbiales, ambigüedad léxica, siglas y nombres propios, los resultados de los tres programas han sido similares. Al comparar los resultados que han tenido los programas utilizados en los diferentes apartados,estas son nuestras conclusiones:
● Ambigüedad léxica: polisemia y homonimia: los ejemplos de traducción de palabras homónimas y polisémicas han presentado algunos problemas, aunque Google ha obtenido mejores resultados que los otros programas. Systran elige la acepción correcta en dos de los ejemplos; Reverso no reconoce el contexto en la mayoría de los ejemplos y lo soluciona traduciendo las diferentes acepciones del término para que el usuario elija la correcta.
● Calcos léxicos y sintácticos: aquí también Google ha obtenido mejores resultados. Las traducciones dadas son de una calidad aceptable.
● Construcciones en voz pasiva: nuevamente, Google resuelve la mayoría de las traducciones sin ningún problema.
● Refranes y modismos: Google solamente encuentra la traducción apropiada para algunos de ellos.Aquí todos los programas se encuentran con las mismas limitaciones originadas en la carencia de conocimiento del mundo. Al traducir palabra por palabra se llega a traducciones totalmente erróneas.
● Colocaciones: Google ofrece traducciones correctas a todos los ejemplos usados, lo que demuestra que sus diccionarios incluyen todas estas unidades de traducción.
● Locuciones adverbiales: en este caso los resultados de los tres programas son similares. Systran, Google y Reverso encuentran la traducción apropiada para algunos de los ejemplos dados pero no para todos. Algunos de los ejemplos los traducen palabra por palabra, perdiendo así el significado original.
● Siglas: en la traducción de siglas todos los programas usados han tenido buenos resultados. Siempre que estas siglas sean comunes, no parece haber problemas de traducción. Cuando aparecen siglas menos comunes, estos traductores no nos pueden ayudar.
● Nombres propios y topónimos: nos encontramos aquí con el mismo tipo de limitaciones. Los nombres propios serán más o menos reconocidos por los traductores automáticos en la medida en que sean más o menos comunes. Los resultados de los tres programas han sido aceptables: Systran los ha traducido pero ha cambiado el sentido al invertir el orden; Google no ha traducido ninguno de los nombres propios aunque sí ha traducido sin problemas todos los topónimos; Reverso también ha traducido la mayoría de ellos.
Aunque en este trabajo solo hemos presentado una muestra de resultados de traducción de frases y oraciones breves del inglés al español, esto nos ha ayudado a confirmar diferentes tipos de errores a los que nos enfrentaremos en la traducción. Habría que seguir analizando cuál es el comportamiento de estos traductores con diferentes tipos de textos. Obviamente, si enfrentamos estos programas a oraciones de mayor grado de complejidad, los resultados serán diferentes y su eficiencia variará en función del tipo de texto y del área temática. Cada tipo de texto presenta una complejidad diferente, difícil de comparar, pero hay errores recurrentes que tendremos que ir identificando. Como ya mencionamos al comenzar este trabajo, la evaluación de programas de traducción automática no es una tarea fácil. La respuesta a la pregunta sobre cuál es el mejor de los programas de traducción automática utilizados no es obvia tampoco.
Para terminar, citamos las palabras de Cerezo (2003: 158159): Evaluar no significa concluir qué producto es mejor frente a otro, sino averiguar qué producto supera (o no) a otro en un aspecto determinado, y recomendarlo (o no) según su adecuación a las necesidades del cliente. A pesar de todas las limitaciones mencionadas, siempre podremos sacar provecho de estos sistemas desde el punto de vista económico y temporal, si [estamos] conscientes de que pueden ser muy útiles para aplicaciones y entornos determinados (López, 2002).
Notas
1 Las citas que no tienen número de página, como esta, son tomadas de documentos en línea. Las referencias completas se encuentran en la sección de Referencias al final del artículo.
2 Disponible también en línea: http://www.scribd.com/doc/9376560/MachineTranslationanIntroductoryGuide
REFERENCIAS
1. Arnold, D., Balkan, L., Meijer, S., Humphreys, R. L. y Sadler, L. (1994). Machine translation. An introductory guide. Oxford, Black well NCC. [ Links ]
2. Bell, N. (2001, octubre). Las nuevas tecnologías en la traducción (Documento en línea). Ponencia presentada en el II Congreso Internacional de la Lengua Española: El español en la sociedad de información, Valladolid. Disponible: http://congresosdelalengua.es/valladolid/ponencias/nuevas_fronteras_del_espanol/1_la_traduccion_en_espanol/bel_n.htm (Consulta: 2010, junio 10) [ Links ]
3. Cardona, G. (1991). Diccionario de lingüística. Barcelona, Ariel. [ Links ]
4. Cerezo, L. (2003). Hacia la evaluación de dos sistemas comerciales de memorias de traducción. En G. Corpas Pastor y M. J. Varela Salinas (comps.), Entornos informáticos de la traducción profesional. Las memorias de traducción (pp. 139-169). Granada: Atrio. [ Links ]
5. Corpas Pastor, G. (1996). Manual de fraseología española. Madrid, Gredos. [ Links ]
6. Diéguez, M. I. y Cabrera, I. (1996). Traducción automática versus traducción humana: Variables que inciden en la elección de uno u otro método de traducción con miras a optimizar el tiempo, costo y calidad de la traducción (Documento en línea). Actas del V Simposio Iberoamericano de Terminología RITerm, 134143. Disponible: http://www.riterm.net/actes/5simposio/dieguez2.htm (Consulta: 2010, mayo 10) [ Links ]
7. Diéguez, M.I. y Cabrera, I. (1998). Traducción automática y traducción mixta: Resultados de un estudio comparativo. Onomázein, 3, 305-314. (Revista en línea). Disponible: http://onomazein.net/3/traduccion.pdf (Consulta: 2010, mayo 10) [ Links ]
8. Diéguez, M. I. y Lazo, R. M. (2004). Tecnologías de la información y de la comunicación (TIC) al servicio del traductor profesional. Onomázein 9, 51-74. (Revista en línea). Disponible: http://onomazein.net/9/tecnologia.pdf (Consulta: 2010, mayo 10) [ Links ]
9. Diéguez, M.I. y Riedemann, K. (1998). Análisis del error en la traducción automática: Algunos ejemplos de las formas ing del inglés al español. Onomázein, 3, 211-229. (Revista en línea). Disponible: http://onomazein.net/3/analisis.pdf (Consulta: 2010, mayo 15) [ Links ]
10. García-González, J. E. (1997-1998). Anglicismos morfosintácticos en la traducción periodística (inglés español): Análisis y clasificación. Cauce: Revista de Filología y su Didáctica 2021, 593-622. (Revista en línea), Disponible: http://cvc.cervantes.es/literatura/cauce/pdf/cauce2021/cauce2021_31.pdf (Consulta: 2009, septiembre 10) [ Links ]
11. Grishman, R. (1991). Introducción a la lingüística computacional (A. Moreno Sandoval, trad.). Madrid, Visor. [ Links ]
12. Hernández, P. (2002). En torno a la traducción automática. Revista del Instituto Cervantes 2. (Revista en línea), Disponible: http://www.infoamerica.org/documentos_pdf/bar07.pdf (Consulta: 2010, mayo 15) [ Links ]
13. Hutchins, J. (2001). Machine translation over fifty years. Histoire Épistémologie Langage, 23(1): 731. (Revista en línea), Disponible: http://www.persee.fr/web/revues/home/prescript/article/hel_07508069_2001_num_23_1_2815 (Consulta: 2010, mayo 1) [ Links ]
14. Hutchins, W.J. y Somers, H.L. (1995). Introducción a la traducción automática. Madrid, Visor. [ Links ]
15. Llisterri, J. (2009). Tecnologías lingüísticas: Las tecnologías del texto (Documento en línea). Disponible: http://liceu.uab.cat/~joaquim/language_technology/HLT/tecnol_ling_texto.html (Consulta: 2010, mayo 5) [ Links ]
16. López, V. (2002). Posibilidades y realidades de la traducción automática. La Linterna del Traductor Revista de Traducción, 3. (Revista en línea), Disponible: http://traduccion.rediris.es/3/tr_au.htm (Consulta: 2010, junio 2) [ Links ]
17. Lyons, J. (1980). Semántica. Barcelona, Teide. [ Links ]
18. McElhaney, T. y Vasconcellos, M. (1988). The translator and the postediting experience. En M. Vasconcellos (comp.), Technology as translation strategy (vol. II, State American Translators Association Scholarly Monograph Series, pp. 140-148). Nueva York: Universidad del Estado de Nueva York. [ Links ]
19. Moreno, A. (2000). Diseño e implementación de un lexicón computacional para lexicografía y traducción automática. Estudios de Lingüística Española 9. (Revista en línea), Disponible: http://elies.rediris.es/elies9/index.htm (Consulta: 2010, junio 2) [ Links ]
20. Oliver, A., Moré, J. y Climent, S. (2008). Traducción y tecnologías. Barcelona, Editorial UOC. [ Links ]
21. Real Academia Española. (2003). Diccionario de la Lengua Española (DRAE) (22ª ed.). Madrid, Espasa Calpe. [ Links ]
22. Valdés, J. (1989). La traducción automática. Biblioteca Universitaria 4(3). (Revista en línea), Disponible: http://www.dgbiblio.unam.mx/servicios/dgb/publicdgb/bole/fulltext/volIV3/traduccion.htm (Consulta: 2009: septiembre 10) [ Links ]
23. Vasconcellos, M. (comp.). (1988). Technology as translation strategy (vol. II, State American Translators Association Scholarly Monograph Series). Nueva York, Universidad del Estado de Nueva York. [ Links ]
