










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkNúcleo
versión impresa ISSN 0798-9784
Núcleo vol.25 no.30 Caracas dic. 2013
¿Es posible predecir la dificultad de preguntas de comprensión de lectura en inglés científico y técnico (ICT) a partir del análisis de su perfil léxico?
Could Difficulty of English for Science and Technology (EST) Reading-Comprehension Test Items be Predicted by Analysing their Lexical Profile?
Yris Casart Quintero1 y Noela Cartaya Febres2
Universidad Simón Bolívar – USB. Departamento de Idiomas. Edif. de Estudios Generales, piso 2. Sartenejas, Caracas 1080-A, Venezuela. Telf.: (58 212) 906 37 80
Resumen
Las investigaciones sobre comprensión de lectura en L1 y L2 atribuyen al perfil léxico de los textos un papel clave en las fórmulas de lecturabilidad, privilegiándolo sobre otras variables (Chall, 1984; Day, 1994; Nuttall, 1996; Read, 1997, entre otros). En el presente estudio se explora la posible correlación estadística entre el perfil léxico y el índice de dificultad de los ítems que integran las pruebas de logro en el contexto de un programa de lectura en inglés científico y técnico dirigido a hispanohablantes. Para ello, se calcularon la relación tipo-muestra; los porcentajes de palabras de alta frecuencia, de vocabulario académico, de vocabulario científico general y de palabras de etimología greco-latina en dichos ítems. Nuestros resultados indican que el perfil léxico per se no determina el nivel de dificultad. Las deficiencias de los aprendices en cuanto a la amplitud de sus inventarios léxicos en la L2 y sus fallas en el reconocimiento de cognados inglés-español podrían dar cuenta de dicho hallazgo. A pesar de que no permite predecir el nivel de dificultad de los ítems, el análisis de su perfil léxico constituye un valioso insumo durante los procesos de generación y evaluación de preguntas de comprensión de lectura para garantizar su idoneidad.
Palabras clave: enseñanza-aprendizaje del inglés como lengua extranjera (ILE) e inglés científico y técnico (ICT), comprensión de lectura en L2, lecturabilidad, perfil léxico y umbral léxico.
Abstract
Research in L1 and L2 reading-comprehension assigns a key role to the vocabulary profile of a text in readability formulas, favoring it over other variables (Chall, 1984; Day, 1994; Nuttall, 1996; Read, 1997; etc.). This study explores a possible statistical correlation between lexical profiles and difficulty indexes of the items in a set of achievement tests of a reading program in English for Science and Technology for Spanish-speakers. With this in mind, type-token ratio; percentage of high-frequency words, academic and scientific vocabulary; and the Greco-Latin index for each item were calculated. Our results show that lexical profiles per se do not determine the level of difficulty of an item. Learners lack of a minimal lexical threshold in L2 and their failure to recognize English-Spanish cognates may account for these results. Although lexical profile analysis does not allow for item difficulty prediction, it is still essential for guaranteeing the suitability of texts during generation and evaluation of reading comprehension questions.
Key words: teaching and learning English as a Foreign Language (EFL) and English for Science and Technology (EST), L2 reading comprehension, readability, vocabulary profile and lexical threshold.
Est-il possible de prédire la difficulté des questions de compréhension de lecture en anglais scientifique et technique (AST) à partir de lanalyse de leur profil lexique ?
Résumé
Les recherches sur la compréhension de lecture en L1 et L2 attribuent un rôle clé au profil lexique des textes dans les formules de lisibilité et le privilégient par rapport à dautres variables (Chall, 1984; Day, 1994; Nuttall, 1996; Read, 1997, entre autres). Dans cette étude, lon explore la possible corrélation statistique entre le profil lexique et lindice de difficulté des items qui font partie des épreuves dans le cadre dun programme de lecture en anglais scientifique et technique pour des hispanophones. Lon a calculé la relation type-échantillon et les pourcentages des mots très fréquents, des mots appartenant au vocabulaire scientifique général et des mots dorigine grecque-latine de ces items-là. Daprès les résultats, le niveau de difficulté nest pas déterminé uniquement par le profil lexique. Les difficultés des étudiants quant à la taille de leurs inventaires lexiques en L2 et leurs problèmes pour reconnaître des semblables anglais-espagnol pourraient avoir aussi de linfluence. Même si lanalyse du profile lexique ne permet pas de prédire le niveau de difficulté des items, celle-ci est un outil important pour poser et pour évaluer des questions de compréhension de lecture et pour garantir quelles seront les plus appropriées.
Mots clés: enseignement-apprentissage danglais langue étrangère (ALE) et danglais scientifique et technique (AST), compréhension de lecture en L2, lisibilité, profil lexique et seuil du lexique.
É possível predizer a dificuldade de perguntas de compreensão de leitura em Inglês Científico e Técnico (ICT) a partir da análise de seu perfil léxico?
Resumo
Nas pesquisas realizadas em relação à compreensão de leitura em L1 e L2 se afirma que o perfil léxico dos textos tem um papel fundamental nas fórmulas de leiturabilidade, dando a ele mais importância que a outras variáveis (Chall, 1984; Day, 1994; Nuttall, 1996; Read, 1997, entre outros). No seguinte estudo se explora a possível correlação estatística entre o perfil léxico e o índice de dificuldade dos itens que fazem parte das provas de conhecimento no contexto de um programa de leitura em ICT voltado a hispanofalantes. Por isso, foi calculada a relação tipo-amostra, as porcentagens de palavras de alta frequência, de vocabulário acadêmico, de vocabulário científico em geral e de palavras de etimologia greco-latina existente nesses itens. Nossos resultados mostram que o perfil léxico per se não determina o nível de dificuldade. As deficiências dos estudantes em relação à amplitude de seus inventários lexicais na L2 e as falhas para reconhecer cognados inglês-espanhol poderiam servir para demonstrar esses resultado. Apesar de não permitir predizer o nível de dificuldade dos itens, a análise do seu perfil léxico é uma importante fonte de informação durante os processos de geração e avaliação de perguntas de compreensão de leitura para garantir sua idoneidade.
Palavras chave: ensino-aprendizagem de inglês como língua estrangeira (ILE) e de inglês científico e técnico (ICT), compreensão de leitura em L2, leiturabilidade, perfil léxico e umbral léxico.
Recibido: 04/03/13
Aceptado: 03/06/13
1. Introducción
El componente de comprensión de lectura de los cursos de inglés como lengua extranjera (ILE), inglés para fines académicos (IFA), inglés para fines específicos (IFE) e inglés científico y técnico (ICT), en las instituciones de educación superior de los países de habla hispana, ha recibido tradicionalmente considerable atención debido a la relevancia de esta destreza para el acceso a contenidos actualizados en los estudios de tercer y cuarto nivel. La relación entre la lecturabilidad1 de un texto en la segunda lengua (L2) y su perfil léxico ha sido estudiada por numerosos investigadores (Alderson, 1984; Laufer, 1989, 1992, 1997; Laufer y Ravenhorst-Kalovsky, 2010; Llinares, 1990; Nation, 2001, 2006; entre otros). Es por ello que un estudio que intente determinar hasta qué punto se puede predecir dicha lecturabilidad con base en el análisis del perfil léxico de un texto ofrece la posibilidad de contar con un método efectivo para seleccionar pasajes de lectura idóneos, ya sea con fines de instrucción o de evaluación de las destrezas de comprensión de lectura.
El estudio que presentamos a continuación, realizado dentro del marco de un programa de lectura en ICT a nivel universitario, se plantea específicamente indagar si es factible establecer una relación entre los diversos factores que constituyen el perfil léxico de los ítems2 que componen las pruebas de logro en comprensión de lectura y el índice de dificultad de estos. Ello permitiría contar con un criterio más eficiente para evaluar esas preguntas. En las distintas secciones a continuación, revisamos los fundamentos conceptuales que subyacen a estas consideraciones y los antecedentes de investigación en nuestro contexto pedagógico. Asimismo, describimos un estudio empírico que nos permitirá tener una idea más precisa sobre la posible relación entre lecturabilidad y perfil léxico, además de las implicaciones pedagógicas que estos hallazgos podrían tener en nuestro contexto particular.
2. Fundamentos conceptuales
2.1 Categorización de las unidades léxicas
Los estudiosos de las lenguas de especialidad se plantean un modelo para categorizar las unidades léxicas de ese tipo de textos que contempla tres categorías generales: el vocabulario técnico, el vocabulario semiespecializado y el vocabulario general de uso estándar en una especialidad. El vocabulario técnico está compuesto por aquellas unidades usadas en un dominio del conocimiento en particular y tienen un único referente conceptual (Gómez González-Jover, 2007). Por ejemplo, en inglés, el inventario más completo en lo que se refiere al discurso científico-técnico es el Science Word List (SWL), del que contamos con una versión preliminar desarrollada por Coxhead y Hirsh (2007). La finalidad detrás del desarrollo de esta lista era determinar si existía un núcleo de palabras de alta frecuencia que sean específicas de los textos de carácter científico en general, pero que no pertenezcan a ninguna área de especialidad dentro de las ciencias en particular. La SWL contiene 318 familias de palabras3 que, en conjunto, proporcionan una cobertura de aproximadamente un 4% de los textos que componen un corpus de textos de carácter científico y técnico.
Por otra parte, el vocabulario semiespecializado está compuesto por términos de carácter académico que se utilizan en más de un dominio y tienen un significado dinámico y dependiente del contexto. En inglés, la lista de referencia para el vocabulario académico es la Academic Word List (AWL) de Coxhead (2000). Esta contiene 570 familias de palabras seleccionadas, al igual que la SWL, de acuerdo con criterios como rango, frecuencia y uniformidad de la frecuencia en un corpus de textos de carácter académico. La AWL fue desarrollada considerando fundamentalmente las necesidades de los aprendices de inglés como segunda lengua o como lengua extranjera que se inician en sus estudios universitarios.
La categoría que corresponde al vocabulario general de uso estándar en una especialidad la componen unidades léxicas que no son técnicas ni semiespecializadas, pero que se encuentran con alta frecuencia. Esta categoría incluye tanto palabras funcionales como palabras de contenido. Según Nation (2001, 2006), el 80% de las palabras de un texto no especializado pertenece a la categoría de palabras de alta frecuencia. En inglés, la lista clásica que representa este conjunto es la General Service List of English Words (GSL) de West (1953), la cual contiene alrededor de dos mil familias de palabras.
2.2 Lecturabilidad y perfil léxico en la literatura
El modelo de categorización de las unidades léxicas de las lenguas de especialidad anteriormente descrito nos ayuda a entender el papel que tiene el perfil léxico de un texto en su lecturabilidad. La "lecturabilidad" (Read, 2000) se refiere a los diversos aspectos que pueden hacer un texto fácil o difícil de leer para un grupo específico de lectores. A pesar de que en la lecturabilidad influyen cantidad de variables relativas a las características estructurales y de contenido del texto, las investigaciones sobre la comprensión de lectura tanto en la lengua materna (L1) como en L2 le han dado preponderancia de manera sistemática al papel que desempeña el perfil léxico (Chall, 1984; Day, 1994; Nuttall, 1996; Read, 1997; entre otros). Para efectos de este estudio, el "perfil léxico" de un texto es la combinación de los factores que determinan sus índices de "variación léxica" y de "composición léxica" (Cartaya y Casart, 2009).
La "variación léxica" o relación tipo-muestra (type-token ratio) no es más que el número total de palabras de un texto (muestras o tokens) dividido entre el número de palabras diferentes que aparecen en el mismo (tipos o types) (Mackey y Gass, 2005). Un texto con un mayor índice de variación léxica contiene una amplia gama de palabras diferentes, mientras que un texto con un menor índice de variación léxica contiene un número limitado de palabras de manera repetitiva. En ese sentido, en la medida que un texto presente una variación léxica mayor, podría resultar más difícil para un aprendiz con limitado conocimiento léxico. Por su parte, la descripción de la "composición léxica" de un texto, en lo que respecta a la frecuencia de aparición de las palabras que lo componen, resulta ser uno de los indicadores más útiles para determinar su grado de dificultad (Alderson, 2000; Chall, 1984). Otro aspecto de la composición léxica que vale la pena considerar en lo que se refiere al aprendizaje de inglés como L2, cuando la L1 del aprendiz es el español, es el índice greco-latino. Este se refiere al porcentaje de palabras en un texto que son cognadas de otras palabras en una lengua romance (Cobb, s.f.).
Todas estas consideraciones han motivado esta investigación en torno a la posible relación entre el índice de dificultad de los ítems de las pruebas de comprensión de lectura en la L2 y el perfil léxico de los textos que los componen. La próxima sección consta de una breve descripción del contexto pedagógico en el que se desarrolla este estudio. A ella le sigue otra sección en la cual se hace un repaso de las investigaciones realizadas en dicho contexto relacionadas con el tema que nos ocupa.
3. El contexto pedagógico
El Departamento de Idiomas de la Universidad Simón Bolívar (USB) imparte un programa de lectura en ICT (PLICT) diseñado para desarrollar progresivamente un conjunto de destrezas en el estudiante del Ciclo Básico que le permitan lograr la comprensión efectiva de textos de carácter científico y técnico en inglés. Las primeras versiones de este programa datan de finales de los años ochenta del siglo pasado y desde entonces consta de tres cursos consecutivos que se ofrecen trimestralmente a lo largo del primer año académico de estudios de ingeniería y ciencias básicas. Son materias obligatorias, puesto que se considera que las destrezas de comprensión de lectura en ILE adquiridas en el programa serán de utilidad para los estudiantes en las asignaturas correspondientes al Ciclo Profesional de sus estudios universitarios. Al inicio del año académico, se administra una prueba de ubicación a toda la cohorte de manera masiva. Con base en los resultados que obtengan en dicha prueba, los estudiantes son eximidos de los tres cursos o ingresan al programa en cualquiera de ellos.
De acuerdo al plan de evaluación de los tres cursos que componen este programa, alrededor del 50% de la calificación final de los estudiantes recae sobre dos pruebas de comprensión de lectura administradas trimestralmente a toda la población estudiantil inscrita en el programa. Estos seis exámenes departamentales son elaborados por la Comisión de Exámenes a partir de un banco de ítems y tienen entre 20 y 25 preguntas cada uno. Las preguntas se componen de un texto corto (de longitud variable entre 40 y 300 palabras), cuya temática corresponde a distintas disciplinas de las ciencias físicas, biológicas o sociales, seguido de una pregunta de selección simple con tres opciones (ver anexo).
4. Antecedentes de investigación en nuestro contexto pedagógico
En el marco del contexto pedagógico descrito en la sección anterior, diversos estudios han abordado el tema de la dificultad de las preguntas de comprensión de lectura desde distintos ángulos.
Soto-Rosa (1991) exploró la validez de las predicciones de los profesores acerca del nivel de dificultad de los ítems. Luego de someter una serie de ítems a la evaluación de docentes con experiencia en nuestro programa de lectura, cotejó sus predicciones con el índice de dificultad de los ítems obtenido luego de ser administrados. El índice de dificultad fue calculado con base en la Teoría Clásica de Medición (Lord y Novick, 1968). De acuerdo con los resultados del estudio de Soto-Rosa, no es posible predecir la dificultad de los ítems sobre la base de los juicios de los docentes. A propósito de sus resultados, Soto-Rosa indica que se requiere trabajar en el desarrollo de un método objetivo para complementar los juicios subjetivos emitidos por los docentes.
Otro estudio que corresponde a nuestro contexto pedagógico examinó la utilidad de las fórmulas de lecturabilidad para estimar el nivel de dificultad de las preguntas de comprensión de lectura empleadas en los exámenes departamentales del PLICT (Brachbill, 1991). Los resultados de dicho estudio indican que no hay una correlación estadísticamente significativa entre el nivel de dificultad de los ítems analizados empleando el instrumento denominado Gráfico de Fry (1963) y el índice de dificultad de las preguntas obtenido a través del patrón de respuestas de los estudiantes. Brachbill concluye que no resulta viable el uso del Gráfico de Fry como indicador de la lecturabilidad para estimar el nivel de dificultad de los ítems en nuestro contexto pedagógico. Además, esta autora considera necesario encontrar otras maneras para predecir el nivel de dificultad de las preguntas de comprensión de lectura. A pesar de que los dos trabajos que acabamos de mencionar no son recientes y no han sido publicados en revistas especializadas, tienen un gran valor para esta investigación puesto que se refieren directamente al contexto pedagógico bajo estudio y corresponden a informes técnicos elaborados por profesores adscritos al programa en cuestión, los cuales además han sido evaluados por especialistas en el área provenientes de diversas instituciones de educación superior.
Más recientemente, en un esfuerzo por evaluar la validez de las pruebas departamentales administradas en el marco de nuestro programa, Cartaya y Casart (2009) concluyeron que las pruebas de comprensión de lectura y los textos que se utilizan para la práctica de la lectura en el primer curso del programa son equivalentes desde el punto de vista léxico. Dicha similitud sugiere una correspondencia en cuanto al nivel de dificultad, dado que las palabras que componen los materiales didácticos y las pruebas se encuentran dentro del mismo rango de frecuencia. Los rasgos léxicos observados en los exámenes departamentales analizados indican que son pruebas de logro adecuadas, desde el punto de vista léxico, para el programa de lectura en cuestión. Asimismo, según Casart, Fung y Trías (2011), la dificultad de los ítems que componen las pruebas no está determinada por la complejidad cognitiva de la tarea de lectura que estos involucran, la cual se ha operacionalizado a través del objetivo de la pregunta.
Por otro lado, en un estudio previo sobre cómo perciben los estudiantes los textos de divulgación científica y de ciencia ficción en inglés, en términos de su dificultad léxica, parecía adelantar que no estaba claro hasta qué punto se podía determinar la lecturabilidad de un texto con base en la frecuencia del vocabulario que lo compone (Cartaya y Llinares, 2006). Aparentemente, aunque la lista de palabras más frecuentes en inglés (West, 1953) está compuesta en un 41% por cognados del español (Cartaya, 2011a), abundan en ella palabras tanto de función como de contenido de raíz sajona que suelen resultar desconocidas al aprendiz principiante. Ello implica que este conjunto de palabras, aunque de alta frecuencia, se convierte en un verdadero obstáculo léxico para nuestros estudiantes quienes, en su gran mayoría, son hispanohablantes.
5. El objetivo del estudio
Como parte de las tareas de mantenimiento del Banco de Ítems adscrito a la Comisión de Exámenes del Departamento de Idiomas, a partir del cual se elaboran las pruebas departamentales, nos vemos en la constante necesidad de generar y evaluar preguntas de comprensión de lectura. Para intervenir de manera más eficiente en ese proceso, nos hemos planteado identificar las variables que pueden incidir de manera directa e indirecta en el índice de dificultad de los ítems en el contexto del programa en cuestión.
Como ya hemos señalado, la literatura sobre los factores que intervienen en la lecturabilidad de un texto le ha dado preponderancia al papel del perfil léxico (Chall, 1984; Day, 1994; Nuttall, 1996; Read, 1997; entre otros), aunque en nuestro contexto pedagógico en particular hayamos obtenido resultados que a simple vista parecen contradictorios (Cartaya y Llinares, 2006). Para completar el panorama que sobre la relación entre el perfil léxico de un texto y su lecturabilidad nos han proporcionado tanto la literatura del área como las investigaciones previas realizadas en el marco del PLICT de la USB, se hace indispensable precisar la naturaleza de esa relación. De existir una relación entre el perfil léxico y la dificultad del ítem, sería posible intervenir de manera más eficiente en el proceso de generación y evaluación de ítems de comprensión de lectura para los exámenes departamentales, puesto que nos permitiría hacer una preselección de textos con base en el perfil léxico para determinar su idoneidad.
En virtud de lo anteriormente expuesto, nuestra pregunta de investigación es: ¿Existe correlación entre el perfil léxico de los textos y el índice de dificultad de los ítems de los exámenes departamentales del PLICT de la USB?
Partiendo de esa interrogante, el objetivo del presente estudio es explorar si se observa una correlación estadísticamente significativa entre el perfil léxico de los textos y el índice de dificultad de los ítems de los exámenes departamentales del PLICT de la USB. Los objetivos específicos de nuestro estudio se detallan a continuación:
a) Calcular los factores que componen el perfil léxico (variación léxica y composición léxica, incluyendo el índice de cognados inglés-español) de los ítems que componen las pruebas de comprensión de lectura.
b) Calcular los factores que componen el perfil léxico de las pruebas de comprensión de lectura de manera global.
c) Cotejar cada uno de los factores del perfil léxico con el índice de dificultad de los ítems individualmente y con el índice de dificultad de las pruebas de comprensión de lectura.
6. Procedimientos metodológicos
Con el propósito de determinar si es válido utilizar el perfil léxico de las preguntas de comprensión de lectura de textos de carácter científico-técnico en inglés como predictor de su nivel de dificultad, utilizamos los datos provenientes de las seis pruebas de comprensión de lectura administradas masivamente a todos los estudiantes (N = 560) inscritos en el PLICT. En su mayoría, los estudiantes que cursan este programa se encuentran en el primer año de sus respectivas carreras, son hispanohablantes y sus edades están comprendidas entre los 17 y 20 años.
Una vez administradas las pruebas, se tomó una muestra al azar que corresponde al 25% de la población (N = 140) para llevar a cabo el análisis estadístico de los ítems a partir del patrón de respuestas. Esta proporción de la población resulta estadísticamente representativa. La muestra estuvo constituida por todos los estudiantes que tomaron la misma versión de la prueba. Cada una de las cuatro versiones tiene los mismos ítems en un orden de presentación distinto. El protocolo de distribución de las pruebas garantiza que la muestra incluya estudiantes de todas las secciones. Este procedimiento de muestreo está validado por los hallazgos de Berríos e Iribarren (1989), según los cuales el orden de presentación de los ítems no determina la distribución de las calificaciones de los estudiantes.
Los datos recogidos a través de las seis pruebas departamentales hicieron posible determinar el nivel de dificultad de los 140 ítems que las componen. El patrón de respuestas de la muestra se analizó a través del uso de un programa informático (Lertap 5 – Nelson, 2000) que arroja estadísticas descriptivas basadas en la Teoría Clásica de Medición. Este análisis permite determinar la calidad global de las pruebas (índice promedio de dificultad y discriminación, confiabilidad, validez, error típico, etc.), así como conocer el comportamiento individual de cada una de los ítems que las componen.
El índice de dificultad de un ítem permite determinar en qué medida este es fácil o difícil. El índice de dificultad se obtiene al dividir el número de estudiantes que contestaron correctamente una determinada pregunta entre el total de estudiantes que la contestaron. Es así como un valor que se acerca a la unidad corresponde a una pregunta más fácil, mientras que un valor que tiende a cero corresponde a una pregunta más difícil. Los ítems se clasificaron según su nivel de dificultad en fáciles, promedio y difíciles, empleando el criterio utilizado por Casart et al. (2011). Un ítem fácil es aquel cuyo índice de dificultad es igual o superior a 0,75 (la pregunta fue respondida correctamente por más del 75% de la muestra). Un ítem de dificultad promedio es aquel cuyo índice de dificultad es igual o mayor a 0,50 pero menor a 0,75. Corresponden al grupo de ítems difíciles aquellos cuyo índice de dificultad está por debajo de 0,50 (respondió correctamente menos del 50% de la muestra).
Los exámenes departamentales, además de servir como instrumento para medir la habilidad de comprensión de lectura de los estudiantes inscritos en el programa en cuestión, constituyen el corpus que analizamos desde el punto de vista léxico con el propósito de indagar si existe una relación entre el perfil léxico de los ítems y su nivel de dificultad. Los textos bajo estudio fueron analizados, tanto de forma global como disgregados por ítems, con el Classic VP English v.3 (Cobb, s.f.)4. Este programa informático está disponible gratuitamente en línea y permite un tipo de análisis que proporciona un conjunto de estadísticas sobre la composición léxica de un texto, tales como el cálculo total de palabras muestra (tokens), el cálculo total de palabras tipo (types), y la relación tipo-muestra (type/token ratio) o índice de variación léxica. El índice de variación léxica resulta de dividir el número de palabras tipo entre el total de palabras muestra que se encuentran en el texto analizado.
Por otra parte, el Classic VP English v.3 clasifica las palabras del texto en cuatro categorías. En la categoría K1 se encuentran las palabras que pertenecen a las mil familias de palabras más frecuentes del inglés. Las palabras que se encuentran entre las mil una y dos mil familias de palabras más frecuentes corresponden a la categoría K2 (West, 1953). Las palabras que figuran en la lista de vocabulario académico (Coxhead, 2000) son asignadas a la categoría AWL. Un cuarto grupo de palabras lo componen aquellas que no se encuentran en ninguna de las listas anteriores. En nuestro análisis, incluimos una quinta categoría (SWL) para las palabras que figuran en el listado de vocabulario científico general (Coxhead y Hirsh, 2007).
Finalmente, este programa también arroja como resultado del análisis de un texto los porcentajes de palabras de etimología anglosajona que lo componen y, su inverso, el índice de palabras de etimología greco-latina. Este último indica el porcentaje de palabras en el texto que pueden ser cognadas de otras en cualquier lengua romance, como el español o el francés. En el cuadro 1 se presenta el resultado del análisis de un ítem utilizando el Classic VP English v.3. Para cada categoría, los datos se organizan por número de familias de palabras en el texto, número de tipos, número de muestras y porcentajes.

Una vez calculado el índice de dificultad de todas las preguntas de comprensión de lectura de las seis pruebas departamentales y realizado el análisis de todos los ítems desde el punto de vista léxico, se procedió a analizar los datos con el programa Statistical Package for the Social Sciences (SPSS – IBM, 2010). Básicamente, mediante el cálculo del coeficiente de correlación de Pearson se examinó la posible correlación estadística entre la dificultad de los ítems y los indicadores de perfil léxico: índices de variación léxica, de composición léxica (porcentajes de palabras K1 y K2, AWL, SWL, palabras fuera de estas listas y el índice de palabras de origen greco-latino).
7. Resultados
Los resultados del análisis de los datos correspondientes a los exámenes departamentales del PLICT indican que no se observa correlación estadísticamente significativa entre los elementos que componen el perfil léxico de las preguntas de comprensión de lectura y su índice de dificultad. Si bien se observa variación tanto en el nivel de dificultad como en el perfil léxico de los ítems, no pareciera haber una relación entre ambas.
7.1 Correlación entre la variación léxica de los ítems y su índice de dificultad
Los resultados de nuestro análisis indican que no hay correlación estadísticamente significativa entre el índice de variación léxica (relación tipo-muestra) de los ítems modulares y su índice de dificultad (p > 0.05). Tampoco se observa correlación entre la variación léxica de las pruebas como un todo y su índice de dificultad global. En el cuadro 2, se presentan los resultados obtenidos al analizar los datos correspondientes a todos los ítems para cada uno de los seis exámenes departamentales. En la última columna de la derecha, se presentan los resultados correspondientes al análisis de las pruebas de manera global.

La inexistencia de correlación entre la variación léxica de las preguntas de comprensión de lectura y su índice de dificultad observada en nuestros datos se puede apreciar a través de los siguientes ejemplos. Al comparar los ítems número 16 y 17, ambos correspondientes a una misma prueba del programa de lectura, se observa que el índice de dificultad de ambas resultó el mismo (0,75). A pesar de que ambos ítems resultaron fáciles de acuerdo con lo que revela su índice de dificultad, no tienen una variación léxica similar. Para el ítem 16 se calculó una variación léxica de 0,78 mientras que la del ítem 17 resultó ser 0,59.
Visto desde otra perspectiva, también se observó que las preguntas de comprensión de lectura con índices de variación léxica iguales resultaron tener niveles de dificultad diferentes. Por ejemplo, los ítems 13, 10 y 9, cuyos índices de variación léxica resultaron iguales (0,61), resultaron difícil (0,44), de dificultad promedio (0,59) y fácil (0,89) respectivamente. Ambos ejemplos se muestran en el cuadro 3.

7.2 Correlación entre composición léxica de los ítems y su índice de dificultad
Nuestros resultados indican que tampoco se observa relación entre la composición léxica de las preguntas de comprensión de lectura y su índice de dificultad. Igualmente, el índice de dificultad promedio de las pruebas de comprensión de lectura no correlaciona con su composición léxica global. En el cuadro 4 se muestran los resultados correspondientes al análisis de la correlación entre la composición léxica de los ítems para cada uno de los seis exámenes departamentales y su dificultad. También se encuentran los resultados correspondientes a las pruebas analizadas de manera global.

En los resultados correspondientes a la quinta prueba, específicamente en lo que se refiere al porcentaje de palabras fuera de las listas, sí se observa correlación inversamente proporcional entre este elemento de la composición léxica y el índice de dificultad (r = -0,450 – p < 0,05). Es importante recordar que un mayor índice de dificultad implica que la pregunta es más fácil. Entonces, el resultado obtenido parece indicar que a mayor porcentaje de palabras fuera de lista, mayor dificultad reviste la pregunta. Este es el único componente del perfil léxico que pareciera correlacionar con el índice de dificultad. Sin embargo, podría tratarse de un hecho aislado, ya que únicamente se observa en una de las seis pruebas analizadas.
Con el fin de ilustrar lo observado con respecto a la composición léxica y el índice de dificultad, a continuación presentamos comparaciones de pares de ítems correspondientes a una misma prueba. Por un lado, escogimos dos ítems cuya composición léxica era diferente y cuyos índices de dificultad correspondían al mismo nivel. Por otro lado, se seleccionó un par de ítems cuyo índice de dificultad corresponde a niveles diferentes, pero con composiciones léxicas similares. Para llevar a cabo la comparación de la composición léxica, se redondearon las cifras que corresponden a los resultados expresados en promedios porcentuales, como aparecen en el cuadro 1, y luego se procedió al cálculo estadístico de ji-cuadrado. Con base en dichos cálculos, se puede establecer que la composición léxica del ítem 10 y del ítem 13 es significativamente diferente (c2 = 51,74 p < 0,0001). No obstante, los dos ítems corresponden al nivel de dificultad promedio. Cabe destacar que el índice de dificultad de ambos ítems es igual (0,65). El cuadro 5 ilustra este resultado.

Por otra parte, en el caso los ítems 25 y 12 (ver cuadro 6), a pesar de que la diferencia en la composición léxica no es significativa (c2 = 8,4), estos ítems corresponden a niveles de dificultad diferentes. El ítem 25 resultó ser difícil (0,48) y el 12 resultó muy fácil (0,93).

7.3 Correlación entre el índice greco-latino de los ítems y su índice de dificultad
Al igual que en los casos anteriores, a pesar de que se observa variación en el índice greco-latino de las preguntas de comprensión de lectura, esta variable no correlaciona con el índice de dificultad de los ítems. Tampoco se observa correlación entre el índice greco-latino de las pruebas y su índice de dificultad. En lo que se refiere al análisis global de las pruebas, todas presentan un porcentaje de cognados cercano al 30%. El cuadro 7 ilustra este resultado.

8. Discusión y conclusiones
A la luz de los resultados presentados en la sección anterior, la principal conclusión de nuestro estudio es que no resulta posible predecir la dificultad de preguntas de comprensión de lectura en ICT a partir del análisis de su perfil léxico. La variación observada en los elementos que componen el perfil léxico de los ítems individualmente, y de las pruebas como un todo, no nos permiten dar cuenta de las variaciones observadas en el nivel de dificultad de las preguntas.
En lo que respecta a la variación léxica de las pruebas de comprensión de lectura, nuestros resultados corroboran lo encontrado por Cartaya y Casart (2009). En ese estudio, las autoras solamente analizaron dos pruebas correspondientes al primer curso del PLICT y obtuvieron una relación tipo-muestra de 0,38. En este caso, se ha analizado la variación léxica de todas las pruebas de comprensión de lectura empleadas en nuestro programa. El índice de variación léxica de dichas pruebas es bastante uniforme, ya que varía dentro de un rango de 0,37 a 0,41. Es decir, la variación léxica de todas las pruebas departamentales que actualmente se utilizan para evaluar el logro de los estudiantes en cuanto a sus destrezas de comprensión de lectura se mantiene dentro de un rango de dificultad intermedia.
Por otra parte, estos resultados nos permiten hacer una descripción más precisa de la composición léxica del tipo de textos que se utiliza para las pruebas de comprensión de lectura de nuestro programa. Con respecto a los porcentajes de vocabulario de alta frecuencia (West, 1953), tenemos que 65% a 75% de las palabras pertenecen de la lista de las primeras mil familias de palabras más frecuentes del inglés (K1). Las palabras que pertenecen a la categoría K2 (el rango entre la mil uno y la dos mil) tienen una cobertura del 4 al 7%. El porcentaje de palabras en nuestro registro que figuran en la lista de vocabulario académico (Coxhead, 2000) representa de 5 a 12%. El porcentaje de palabras correspondientes a la lista de vocabulario científico es menor al 3%. Por último, el porcentaje de palabras que no se encuentran en ninguna de las listas mencionadas tiene un rango que va del 10 al 14%. Estos hallazgos también se corresponden con los resultados obtenidos por Cartaya y Casart (2009) al analizar solo las pruebas que se administran para el primer curso. En esa oportunidad, no se incluyó en el análisis el vocabulario científico. Al comparar la composición léxica de nuestro registro con la observada por Nation (2001) al analizar textos de tipo académico (ver cuadro 8), encontramos que los valores obtenidos por dicho autor entran dentro de los rangos observados para nuestro registro textual.

Nuestros hallazgos también parecen confirmar lo apuntado por Brachbill (1991) y Cartaya y Llinares (2006) con respecto a la ineficacia en nuestro contexto de las fórmulas de lecturabilidad basadas en el perfil léxico de los textos y desarrolladas para lectores nativos del inglés. Estas autoras afirman que una de las razones por las que no resultan apropiadas es porque las palabras cortas de etimología anglosajona resultan difíciles para los estudiantes cuya L1 es el español, aunque sean palabras de alta frecuencia. Para un hispanohablante deberían resultar más fáciles las palabras de origen grecolatino, aunque sean menos frecuentes en inglés. Es por ello que sería lógico pensar que un ítem con mayor concentración de cognados inglés-español resultaría más fácil para los estudiantes del programa. Sin embargo, de acuerdo con nuestros resultados, el porcentaje de cognados tampoco es un indicador de dificultad. Una posible explicación para este hallazgo puede ser el hecho de que los hispanohablantes aprendices de ICT suelen fallar en el reconocimiento de cognados, probablemente debido a una escasa amplitud léxica tanto en su L1 como en la L2 (Cartaya, 2011a).
Como parte de esta evaluación de las fórmulas de lecturabilidad basadas en el perfil léxico del texto, consideramos pertinente no perder de vista otra de las posibles razones por las que no nos permiten predecir el índice de dificultad de las preguntas de comprensión de lectura. Cuando aplicamos una de estas fórmulas de lecturabilidad, solamente se pueden controlar aquellas variables asociadas al texto, pero no se pueden controlar las variables asociadas al lector. Por ejemplo, es posible regular la complejidad gramatical, la longitud de las oraciones y el perfil léxico de un texto, pero no se puede prever el umbral lingüístico, ni el umbral léxico del lector. Es por ello que vale la pena tener en cuenta la hipótesis del umbral léxico en la L2 en lo que respecta a la comprensión de lectura. Esta ha sido definida por varios autores como el nivel mínimo de conocimiento léxico que los aprendices de una L2 deben alcanzar con el objeto de lograr un nivel aceptable de comprensión (Cartaya, 2011b). Diversos estudios en las últimas dos décadas han girado en torno a qué representa ese umbral mínimo en términos de amplitud léxica y cobertura textual. Se ha determinado que ese umbral consiste en el conocimiento léxico receptivo de alrededor de 3000 a 5000 familias de palabras de alta frecuencia, puesto que ello le representaría al aprendiz la comprensión del 95% al 98% de las palabras que componen un texto auténtico en la L2. El 95% de cobertura textual constituye el mínimo necesario para lograr un nivel aceptable de comprensión, mientras que 98% le representa un nivel óptimo que le brinda la posibilidad de hacer inferencias conceptuales precisas y convertirse en un lector independiente (Laufer y Ravenhorst- Kalovsky, 2010; Nation, 2006; Nation y Waring, 1997). Esto parece indicar que, en nuestro contexto, una fórmula de lecturabilidad que incluya el perfil léxico del texto podría funcionar muy bien si los estudiantes contaran con el umbral léxico mínimo necesario. Llinares, Leiva, Cartaya y St. Louis (2008) encontraron que nuestros estudiantes suelen tener un inventario léxico insuficiente cuando inician sus estudios universitarios: una media de 9,5 puntos en una prueba de conocimiento léxico en la L2 cuya calificación máxima es 50 puntos.
9. Implicaciones pedagógicas y recomendaciones
Aunque el hallazgo principal de este estudio es que el análisis del perfil léxico de los textos que componen las pruebas no nos permite per se predecir el nivel de dificultad de las preguntas de las pruebas de logro en comprensión de lectura en la L2, sí se derivan de él una serie de otras conclusiones que tendrían implicaciones pedagógicas pertinentes en nuestro contexto.
En vista de que el análisis del perfil léxico no permite predecir el nivel de dificultad de las preguntas de comprensión de lectura con el fin de decidir si estas deberían ser incluidas en futuras pruebas, nos permitimos sugerir que se empleen otros mecanismos tales como la validación de expertos y de campo con ese propósito (Berríos y Casart, 2009). Sin embargo, estimamos recomendable llevar a cabo el análisis de los textos desde el punto de vista léxico como parte del proceso de generación y evaluación de ítems. Por un lado, es posible obtener información valiosa y pertinente como insumo para seleccionar textos para la generación de preguntas de comprensión de lectura empleando el Classic VP English v.3. (Cobb, s.f.), u otra herramienta de este tipo, de manera sencilla y automática. Por otro lado, dicho procedimiento permitiría garantizar la idoneidad de los ítems desde el punto de vista léxico para evaluar el logro en el desarrollo de destrezas de comprensión de lectura en nuestro contexto pedagógico.
Por ahora, no hemos encontrado en el perfil léxico el "mecanismo objetivo" para determinar a priori el índice de dificultad de los ítems de los exámenes departamentales que Brachbill (1991) y Soto-Rosa (1991) recomendaban explorar. Sin embargo, a la luz de nuestros hallazgos, sí pareciera relevante y pertinente insistir en la necesidad de intervenir directamente en el desarrollo de la amplitud léxica del estudiante en la L2, como apuntan Llinares et al. (2008), y en la L1, como recomiendan Cartaya (2011a) y Cartaya y Llinares (2006). También valdría la pena concientizar a los aprendices del PLICT sobre la importancia del reconocimiento de cognados inglés-español. Dirigir nuestros esfuerzos en ese sentido no solo sería útil para nuestro programa, sino que constituye una línea de investigación muy pertinente en nuestro contexto pedagógico.
Agradecimientos
Agradecemos a la Lic. Mayte Mejías por la colaboración prestada en los análisis estadísticos del presente estudio y a la Lic. Iride Capacho por su colaboración en el análisis del perfil léxico de las pruebas.
Notas
1 La "lecturabilidad" se refiere al nivel de dificultad de compresión de un texto para un determinado grupo de lectores. No debe confundirse con la noción de "legibilidad", que se refiere a aspectos ortotipográficos del texto.
2 Para los efectos de este artículo, los términos "ítem" y "pregunta de comprensión de lectura" son equivalentes.
3 Una familia de palabras consiste en una unidad abstracta de análisis morfológico basada en una colección de formas diferentes: una palabra base o raíz, sus inflexiones y derivaciones transparentes (Nation y Waring, 1997). Por ejemplo, la familia de palabras usualmente representada con la palabra attain en inglés incluye attainable, attained, attaining, attainment, entre otras.
4 Una adaptación de Heatley, A. y Nation, P. (1994). Range. Wellington, Nueva Zelanda: Victoria University of Wellington. [Software informático, disponible en http://www.victoria.ac.nz/lals/].
Referencias
1. Alderson, J. C. (1984). Reading in a foreign language: A reading problem or a language problem? En J. C. Alderson y A. H. Urquhart (comps.), Reading in a foreign language (pp. 1-27). Londres: Longman. [ Links ]
2. Alderson, J. C. (2000). Assessing reading. Cambridge: Cambridge University Press. [ Links ]
3. Berríos, G. y Casart, Y. (2009). Diagrama general del Banco de Ítems (Informe técnico no publicado). Caracas: Universidad Simón Bolívar, Departamento de Idiomas. [ Links ]
4. Berríos, G. e Iribarren, I. C. (1989). El efecto del orden de presentación en el diseño de exámenes. Perfiles: Revista de Educación, 19-20, 5-21. [ Links ]
5. Brachbill, P. (1991). Un estudio de la aplicación de técnicas de lecturabilidad para estudiantes de inglés como idioma extranjero en la Universidad Simón Bolívar (Trabajo de ascenso no publicado). Universidad Simón Bolívar, Caracas. [ Links ]
6. Cartaya, N. (2011a). Estudio léxico contrastivo inglés-español: Los cognados en la adquisición léxica del Inglés Científico-Técnico (Tesis doctoral no publicada). Universidad de León, León, España. [ Links ]
7. Cartaya, N. (2011b). La hipótesis del umbral léxico en la comprensión de lectura en la L2. Lingua Americana, 28, 103-118. [ Links ]
8. Cartaya, N. y Casart, Y. (2009). Rasgos léxicos del material de instrucción y de las pruebas de logro de comprensión de lectura en un curso de Inglés Científico y Tecnológico. Anales de la Universidad Metropolitana, 9(1), 115–132. [ Links ]
9. Cartaya, N. y Llinares, G. (2006). Dificultad léxica de textos de divulgación científica y ciencia ficción: Estudio comparativo. Lenguas Modernas, 31, 21-39. [ Links ]
10. Casart, Y., Fung, P. y Trías, M. (2011). La complejidad de la tarea cognitiva y el nivel de dificultad de preguntas en la evaluación de comprensión de lectura en Inglés Científico y Técnico (ICT). Paradigma, 32(2), 21-36. [ Links ]
11. Chall, J. (1984). Readability and prose comprehension: Continuities and discontinuities. En J. Flood (comp.), Understanding reading comprehension: Cognition, language and the structure of prose (pp. 233-264). Newark, DE: International Reading Association. [ Links ]
12. Champeau, C., Marchi, G. y Arreaza, M. (1994). Un banco de ítems para medir la habilidad para la lectura de textos en inglés técnico y científico: Un sistema de clasificación. Argos, 20, 27-49. [ Links ]
13. Cobb, T. (s.f.). Classic VP English v.3 [programa informático en línea]. Disponible: http://www.lextutor.ca/vp/ [Consulta: febrero de 2012] [ Links ]
14. Coxhead, A. (2000). A new academic word list. TESOL Quarterly, 34(2), 213-238. [Enlace a la lista: http://www.victoria.ac.nz/lals/resources/academicwordlist/]. [ Links ]
15. Coxhead, A. y Hirsh, D. (2007). A pilot science-specific word list. Revue française de linguistique appliquée, 12(2), 65-78. [ Links ]
16. Day, R. R. (1994). Selecting a passage for the EFL reading class. English Teaching Forum, 32(1), 20-23. [ Links ]
17. Fry, E. (1963). Teaching faster reading. Cambridge: Cambridge University Press. [ Links ]
18. Gómez González-Jover, A. (2007). Léxico especializado y traducción. En E. Alcaraz, J. M. Martínez y F. Yus (comps.), Las lenguas profesionales y académicas (pp. 27-40). Barcelona, España: Ariel. [ Links ]
19. IBM. (2010). Statistical Package for the Social Sciences, v. 19. (Software informático). [ Links ]
20. Laufer, B. (1989). What percentage of text lexis is essential for comprehension? En C. Lauren y M. Nordman (comps.), Special language: From humans thinking to thinking machines (pp. 316-323). Clevedon: Multilingual Matters. [ Links ]
21. Laufer, B. (1992). How much lexis is necessary for reading comprehension? En H. Bejoint y P. Arnaud (comps.), Vocabulary and applied linguistics (pp. 126-132). Londres: Macmillan. [ Links ]
22. Laufer, B. (1997). Whats in a word that makes it hard or easy? Some intralexical factors that affect the learning of words. En N. Schmitt y M. McCarthy (comps.), Vocabulary: Description, acquisition and pedagogy (pp. 140-155). Cambridge: Cambridge University Press. [ Links ]
23. Laufer, B. y Ravenhorst-Kalovsky, G. (2010). Lexical threshold revisited: Lexical text coverage, learners vocabulary size and reading comprehension. Reading in a Foreign Language, 22(1), 15-30. [ Links ]
24. Llinares, G. (1990). Estudio del "umbral lingüístico" necesario para la comprensión de textos en inglés. Actas del II Congreso Nacional de Profesores de Lenguas Extranjeras con Fines Específicos (pp. 139-143). Caracas: Universidad Simón Bolívar. [ Links ]
25. Llinares, G. y Berríos, G. (1990). Writing MCIs for reading tests in science and technology. English Teaching Forum, 28(4), 43-45. [ Links ]
26. Llinares, G., Leiva, B., Cartaya, N. y St. Louis, R. (2008). Acquisition of L2 vocabulary for effective reading: Testing teachers classroom practice. The Reading Matrix, 8(2), 55-69. [ Links ]
27. Lord, F. M. y Novick, M. R. (1968). Statistical theories of mental test scores. Reading, MA: Addison-Welsley. [ Links ]
28. Mackey, A. y Gass, S. (2005). Second language research: Methodology and design. Mahwah, NJ: Lawrence Erlbaum. [ Links ]
29. Nation, P. (2001). Learning vocabulary in another language. Cambridge: Cambridge University Press. [ Links ]
30. Nation, P. (2006). How large a vocabulary is needed for reading and listening? The Canadian Modern Language Review, 63, 59-82. [ Links ]
31. Nation, P. y Waring, R. (1997). Vocabulary size, text coverage and word lists. En N. Schmitt y M. McCarthy (comps.), Vocabulary: Description, acquisition and pedagogy (pp. 6-19). Cambridge: Cambridge University Press. [ Links ]
32. Nelson, L. (2000). Item analysis for tests and surveys using Lertap 5. Perth, Australia: Curtain University of Technology. [ Links ]
33. Nuttall, C. (1996). Teaching reading skills in a foreign language (2a. ed.). Oxford: Heinemann. [ Links ]
34. Read, J. (1997). Vocabulary and testing. En N. Schmitt y M. McCarthy (comps.), Vocabulary: Description, acquisition and pedagogy (pp. 303-320). Cambridge: Cambridge University Press. [ Links ]
35. Read, J. (2000). Assessing vocabulary. Cambridge: Cambridge University Press. [ Links ]
36. Soto-Rosa, N. (1991). Predicciones de profesores de lectura en inglés como lengua extranjera sobre niveles de dificultad de ítems modulares (Trabajo de ascenso no publicado). Universidad Simón Bolívar, Caracas. [ Links ]
37. West, M. (1953). A general service list of English words. Londres: Longman, Green & Co. [ Links ]
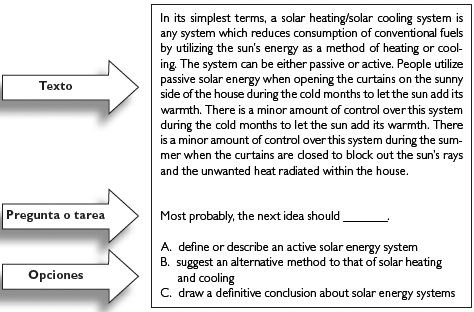
Modelo de ítem modular
Los ítems modularesi se componen de un texto corto, de longitud variable entre 40 y 300 palabras, seguido de una pregunta de selección simple con tres opciones.
El ítem que presentamos a continuación está compuesto por un texto cuya temática es relativa a la ingeniería mecánica. Según el sistema de clasificaciónii que utiliza el Banco de Ítems del Departamento de Idiomas de la USB, las funciones retóricas que predominan en el texto de este ítem modelo son la definición y la descripción, aunque también se observan elementos propios de clasificación y comparación-contraste. La pregunta, por su parte, se clasifica como perteneciente a la categoría de macroinformación, ya que involucra tareas de interpretación en las que el estudiante debe predecir lo que podría seguir a partir de información implícita en el texto.
i Llinares y Berríos (1990).
ii Champeau, Marchi y Arreaza (1994).
