Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkNúcleo
versão impressa ISSN 0798-9784
Núcleo v.19 n.24 Caracas 2007
El grupo nominal complejo y sus implicaciones para la lectura de textos de ciencia
The complex noun group and its implications for the reading of scientific texts
Marta Trías
Departamento de Idiomas Universidad Simón Bolívar – USB Edif. Estudios Generales, 2º piso, of. 207-C Baruta, Edo. Miranda, Venezuela Apartado Postal Nº 89000 Telf. (58 212) 906 37 89 /Fax (58 212) 906 37 80 mtrias@usb.ve
RESUMEN
El grupo nominal complejo concentra información clave para la interpretación del texto académico científico y le imprime la identidad de la comunidad discursiva; es por ello que el alto número de grupos nominales complejos en este tipo de texto es considerado como la característica más resaltante del texto académico científico (Halliday y Martin, 1993). Al comparar el grupo nominal complejo en inglés y en español es posible notar diferencias importantes, las cuales pueden obstaculizar la comprensión de lectura de un texto científico escrito en inglés. Tomando en cuenta esta dificultad se diseñó una investigación en la cual se escogieron dos grupos de estudiantes universitarios hispanohablantes y sólo uno de ellos recibió instrucción especial en la decodificación del grupo nominal complejo. El estudio tenía como finalidad observar si el entrenamiento en la interpretación correcta de los grupos nominales complejos se relacionaba con la mejora en la comprensión de lectura. Los resultados de comparar el desempeño de ambos grupos de estudiantes revelaron un leve incremento en la comprensión de lectura de textos científicos escritos en inglés por parte de aquellos estudiantes que recibieron el entrenamiento.
Palabras clave: grupo nominal, texto científico, lectura
ABSTRACT
Complex noun groups provide an important source of information for the interpretation of scientific academic texts, and also about the identity of the discourse community. The high number of complex noun phrases in academic scientific texts is considered the most outstanding characteristic of this type of text (Halliday and Martin, 1993). A comparison of the way in which complex noun groups are formed in English and Spanish shows that there are a number of relevant differences that may interfere with the comprehension of academic scientific texts by Spanish speaking readers. With this difficulty in mind, two groups of Spanish speaking university students were chosen to conduct a study with the aim of observing whether an appropriate instruction in the interpretation of complex English noun groups could be related to an improvement in reading comprehension of scientific academic texts. The results of the study show a small, yet significant improvement in comprehension by the group of students who received special training.
Key words: noun group, scientific text, reading
Le groupe nominal complexe et ses effets sur la lecture des textes scientifiques
RÉSUMÉ
Le groupe nominal complexe comprend des informations clés pour linterprétation du texte académique scientifique et lui imprime lidentité de la communauté discursive. Cest pourquoi le nombre si élevé des groupes nominaux complexes dans ce type de texte est considéré comme la caractéristique la plus importante du texte académique scientifique (Halliday et Martin, 1993). Une comparaison entre le groupe nominal complexe en anglais et en espagnol montre des différences significatives qui peuvent gêner la compréhension dun texte scientifique écrit en anglais. Vu cette difficulté, lon a développé une recherche avec deux groupes détudiants universitaires hispanophones, dont un seul a reçu une instruction spéciale sur la décodification du groupe nominal complexe. Létude visait à observer si la préparation à linterprétation correcte des groupes nominaux complexes était liée à lamélioration de la compréhension des textes. Après une comparaison du travail de ces deux groupes détudiants, lon a constaté une légère augmentation du niveau de compréhension des textes scientifiques écrits en anglais chez les étudiants qui avaient reçu lentraînement.
Mots clés: groupe nominal, texte scientifique, lecture
O grupo nominal complexo e suas implicações para a leitura de textos de ciência
RESUMO
O grupo nominal complexo concentra informação essencial para a interpretação do texto acadêmico científico e lhe confere identidade dessa comunidade discursiva. Isto justifica o alto número de grupos nominais complexos neste tipo de textos, o que é considerado uma das características mais destacáveis do texto acadêmico científico (Halliday e Martin, 1993). Quando se compara o grupo nominal complexo em inglês e em espanhol é possível notar diferenças consideráveis que, muitas vezes, podem obstaculizar a compreensão de leitura de um texto científico escrito em inglês. Levando em conta esta dificuldade, foi pensada esta pesquisa na qual se escolheram dois grupos de estudantes universitários hispano-falantes e somente um deles recebeu instrução especial para a decodificação do grupo nominal complexo. O estudo visava observar se o treinamento para a interpretação certa dos grupos nominais complexos tinha uma relação com a melhora na compreensão de leitura. Depois de comparar o desempenho dos dois grupos de estudantes, os resultados mostraram que os estudantes que receberam o treinamento tiveram um leve aumento na compreensão de leitura de textos científicos escritos em inglês.
Palavras-chave: grupo nominal, texto científico, leitura
Recibido: 23/05/07 Aceptado: 25/09/07
1. INTRODUCCIÓN
La necesidad de que los estudiantes universitarios puedan consultar libros de texto o publicaciones periódicas especializadas escritas en inglés requiere de la enseñanza de destrezas de comprensión lectora en los programas de inglés con fines académicos y específicos. Sin embargo, para poder lograr un mejoramiento exitoso en las destrezas de lectura en el ámbito universitario, es menester estudiar las características más resaltantes del discurso académico. Tal como revela la bibliografía consultada, una de las características predominantes del discurso de ciencia es la alta frecuencia de grupos nominales complejos, los cuales concentran y aportan información específica relevante para la comprensión (Albentosa y Moya, 2000; Colombi, 2002; Halliday y Martin, 1993; Myers, 1992; Ventola, 1996). Según Halliday y Martin (1993) no es el léxico especializado lo que caracteriza al discurso científico, sino el uso de ciertos recursos gramaticales y sintácticos, los cuales no se despliegan en la oración, ni siquiera en la cláusula, sino que se concentran dentro del grupo nominal, haciendo mucho más denso a éste, a la cláusula y a todo el texto. En otras palabras, el discurso científico es difícil de comprender, no tanto por la terminología especializada o por la cantidad de conocimiento previo requerido, sino porque está construido con un gran número de grupos nominales muy complejos, los cuales forman parte, a su vez, de construcciones sintácticas también muy complejas. Con el fin de ilustrar la afirmación anterior, a continuación se muestra un párrafo de un texto proveniente de una publicación científica:
Application of magnetic fields during the growth of crystal from molten sources may control irregularities in single- crystal semiconductor materials. In experiments at Hughes, a magnetic field was applied for the first time to a floatzone of gallium doped silicon crystals. The magnetic field substantially reduced the amplitude of striations due to crystal rotation and thermal convection. It also made for orderly rotational situations.
Schnepf y Schnöckel (2002: 3.532)
Tal como se puede observar, los grupos nominales complejos ocupan la mayor parte del párrafo y sólo quedan como grupos verbales lo resaltado e negritas. La razón de este desbalance entre grupos nominales y grupos verbales se puede explicar si se toma en cuenta la gran cantidad de información pertinente contenida en los primeros y la presencia de extensa nominalización. El discurso científico recurre a la nominalización y a la metáfora gramatical como formas de: 1) dar por hecho información conocida entre lector y escritor; 2) presentar ideas complejas y abstractas; 3) distanciarse de los actores, y 4) resaltar los procesos para dar una visión objetiva de la actividad científica (Bloor y Bloor, 1995; Halliday y Martin, 1993). Debido a estas características del discurso científico, es necesaria una educación que alcance niveles complejos de alfabetización de tipo académico con el fin de que los estudiantes universitarios puedan abordar textos más complejos. Se requiere de un esfuerzo cognitivo importante por parte de los lectores, aun en su lengua materna, para poder "desempacar"1 (Ventola, 1996) la información contenida en el grupo nominal a través del replanteamiento de éste en proposiciones simples. En el área de la enseñanza de inglés como lengua extranjera, las repercusiones son aún mayores, no solamente porque el grupo nominal complejo es difícil de decodificar, sino por la diferencia entre la forma de organizar el grupo nominal en español y en inglés. Beke (2002) hace referencia al hecho de que los grupos nominales complejos representan una dificultad para los estudiantes universitarios hispanohablantes debido a que la modificación del grupo nominal en inglés y en español se lleva a cabo de maneras diferentes e incluso opuestas. Al respecto sostiene que mientras en el español se procesan las palabras en una relación sincrónica, "el inglés, sin embargo, le exige al lector hispanohablante mayor esfuerzo para procesar la información, pues no siempre se da esta sincronización, especialmente en el contexto de nominalizaciones complejas" (2002: 8). El lector hispanohablante debe automatizar la decodificación de los grupos nominales y canalizar sus esfuerzos hacia otras estrategias, tales como la inferencia y la recuperación de la información para la adecuada reconstrucción del mensaje (Jullian, 2002).
Con el fin de relacionar los elementos sintácticos con la lectura de textos de ciencia, se llevó a cabo una investigación que permitiera explorar las posibles relaciones entre el conocimiento del grupo nominal complejo en inglés y la lectura de textos del área de ciencia por parte de lectores hispanohablantes. Se partió de la premisa de que, si el discurso científico se caracteriza por la profusión de grupos nominales complejos con alta concentración de información, entonces podría pensarse que el entrenamiento en la interpretación correcta de los grupos nominales complejos pudiera ser un elemento importante para la comprensión general de este tipo de discurso.
2. IMPORTANCIA DEL CONOCIMIENTO SINTÁCTICO
Estudios en el área de lectura (Bialystok, 1990; Lemke, 1997; Nuttal, 1982; van Dijk y Kintsch, 1983) sostienen que existen razones para afirmar que el texto requiere ser procesado en unidades, y que mientras más grandes sean las unidades de decodificación, habrá mayor comprensión, pues el lector puede dejar mayor capacidad cognitiva libre para las estrategias de lectura, o para procesar los elementos provenientes de otras fuentes de conocimiento e información. Por el contrario, si el lector decodifica unidades más pequeñas como las palabras, su comprensión será más lenta y limitada. Bialystok (1990) y van Dijk y Kintsch (1983) opinan que el procesamiento de la lectura está limitado por los mecanismos inherentes al procesamiento humano del lenguaje, y que este procesamiento trabaja con el grupo como unidad. Esta afirmación posee implicaciones cognitivas y didácticas para la enseñanza del grupo nominal complejo en inglés con fines académicos, pues se podría deducir que al enseñar al estudiante a interpretar correctamente el grupo nominal complejo, ya no decodificarían palabras, sino unidades mayores, organizando sus conocimientos lingüísticos a través de principios estructurales, lo cual caracteriza al lector eficiente, tal como recomienda Bialystok (1990: 125) al expresar lo siguiente: "los estudiantes que están en el proceso de explicar y organizar el conocimiento lingüístico, pueden beneficiarse de las formas de instrucción que presenten las reglas y las estructuras como principios organizativos".2 Lemke (1997), por su parte, hace énfasis en la importancia de la enseñanza de la lectura de textos en el área de ciencia a través del análisis de los grupos nominales complejos, específicamente ante la presencia de la nominalización: "Es sólo con larga práctica en contextos de uso relativamente específicos que la gente se puede llegar a sentir más a gusto con un estilo tan altamente nominalizado".3 Siendo el discurso científico tan rico en grupos nominales complejos, el entrenamiento en la decodificación de este tipo de estructuras podría aumentar su capacidad de comprensión de lectura.
3. DIFERENCIAS ENTRE EL GRUPO NOMINAL EN INGLÉS Y EL GRUPO NOMINAL EN ESPAÑOL
El grupo nominal es una unidad dentro de la estructura jerárquica de rango ubicado entre la palabra y la cláusula; cumple típicamente las funciones de sujeto o complemento y tiene como componentes un núcleo, determinante y modificadores (Bloor y Bloor, 1995). Ese mismo grupo nominal puede llegar a ser altamente complejo por medio del uso de la subordinación de otras estructuras de mayor jerarquía que el grupo, tales como la cláusula. No obstante, al comparar la forma de organizar los modificadores del grupo nominal en inglés con la forma de organizar los modificadores del grupo nominal en español, se puede observar que mientras que en el idioma inglés hay una fuerte tendencia hacia la premodificación como forma de concentrar información en el grupo nominal, en español se prefiere la pos-modificación. Por ejemplo, complex organic compounds = compuestos orgánicos complejos. Una vez que se agota la premodificación, y con la finalidad de evitar ambigüedad y consecuente pérdida de información, entonces el inglés recurre a la pos-modificación (Quirk, 1972). El español, por su parte, favorece más bien el uso de la pos-modificación, ya sea con elementos simples o con elementos más complejos como la subordinación y las cláusulas relativas, tal como se aprecia en el siguiente ejemplo: morning train = el tren que sale en la mañana /el tren matutino. A pesar de que hay casos, tanto en inglés como en español, en los que el orden fijo varía, esta variación del orden regular constituye una excepción, o un uso limitado a ciertas construcciones; y en español este cambio con frecuencia va acompañado de un matiz diferente de significado (Hernanz y Brucart, 1987).
Es necesario apuntar que la premodificación en el idioma inglés no sólo es extensa, sino que la relación entre premodificadores y entre los premodificadores y el núcleo puede ser poco explícita (Beke, 2002; Hamilton- Toovey y Mateluna, 2001; Izquierdo y Bailey, 1998; Jullian, 2002; Trimble, 1985), por lo cual es necesario un proceso de inferencia. De hecho, los casos de desempaque de los premodificadores pueden llegar a ser tan confusos y ambiguos que solamente pueden ser descifrados por los especialistas en el campo en cuestión.
De acuerdo con la forma como los modificadores se agrupan alrededor del núcleo del grupo nominal en inglés, y de acuerdo con lo observado en la actividad docente en el área de lectura de inglés con fines académicos, es posible predecir algunos elementos que constituyen fuente potencial de dificultad para los lectores hispanohablantes en el campo de ciencia y tecnología:
1) La forma verbal -ing, no finita, en función premodificadora y como cláusula. Algunos casos de la versatilidad de la forma -ing son los siguientes: a) La terminación -ing es una de las formas como el inglés nominaliza, por ejemplo: the breaking up of a planet = la dispersión de un planeta. b) La forma -ing puede aparecer como parte del premodificador, bien sea de manera directa como en el caso de existing telescopes, o como parte de una estructura de premodificación como en el siguiente caso: relatively cool X-ray emitting gas = un gas relativamente frío que emite rayos X; c) Puede también ocurrir en el posmodificador, como en el siguiente ejemplo: a molecule containing carbon = una molécula que contiene carbón. d) La forma -ing puede ocurrir simultáneamente como pre y posmodificador, como en el siguiente ejemplo, en el cual actúa como forma adjetival en el premodificador y como cláusula no finita en el posmodificador: a racing car traveling at 200 km. per tour = un carro de carreras que viaja a una velocidad de 200 km. por hora. Estas estructuras son posible fuente de dificultad para los lectores hispanohablantes, ya que éstos identifican la forma -ing como un participio presente perteneciente al presente progresivo, y no como una cláusula relativa o un grupo preposicional. Puede llegar a ser aún más confuso en aquellos casos en los cuales aparece dos veces la forma –ing: como parte de un presente progresivoy como un sustantivo, tal como en el ejemplo siguiente: they were evolving into bipedal walking = estaban evolucionando hacia el caminar bípedo.
2) Los casos en los cuales el posmodificador es una cláusula encabezada por un participio pasado, la cual contiene una cláusula relativa tácita, tal como se presenta en el siguiente caso: rocks contained in earth layers = rocas ubicadas en las capas de la tierra.
3) Las formas del genitivo como premodificador de un núcleo. Estas construcciones deben ser interpretadas en español a través de un grupo preposicional. Por ejemplo, the earths dynamic system = el sistema dinámico de la tierra.
4) Los casos de sustantivos como premodificadores de otros sustantivos. Este tipo de estructura es muy poco productiva en español y está mayormente relacionada con la composición nominal. Para poder decodificar un grupo nominal en inglés que tenga sustantivos en posición de premodificador, es necesario identificar el núcleo del grupo y luego recurrir a más de un grupo preposicional u otras construcciones de acuerdo con la relación semántica entre los diferentes sustantivos que modifican al núcleo, tal como puede apreciarse en el siguiente ejemplo: polymer sheet extrusion system = sistema de laminado de polímeros por extrusión.
Con la finalidad de minimizar los efectos del contraste entre los grupos nominales en ambos idiomas, así como permitir que los estudiantes dirijan sus esfuerzos cognoscitivos a otros elementos del discurso, es necesario un entrenamiento con el fin de comparar la forma como se organiza el grupo nominal complejo en inglés y en español, y la forma de decodificar los grupos nominales complejos en inglés.
4. EL ESTUDIO
Según la forma de abordar la investigación, el presente estudio es de tipo analítico pues distingue y separa un componente importante en el discurso científico (el grupo nominal) y lo hace materia de estudio. La investigación reportada es a la vez de tipo sintético pues pretende colocar el elemento individual objeto de estudio para reconstruir un todo, es decir, la comprensión de un texto en lengua extranjera. Según los objetivos que persigue es heurístico e inductivo pues se propone descubrir patrones que permitan determinar la incidencia que tiene el conocimiento de la estructura del grupo nominal en la lectura de textos de ciencia escritos en inglés. Con este estudio se esperaba descubrir elementos que permitieran hacer generalizaciones posteriores; no partía de una hipótesis, sino más bien de la suposición de que los estudiantes que poseen un conocimiento del grupo nominal complejo en inglés estarían más capacitados para comprender el discurso científico.
4.1 Participantes
La población que participó en el estudio reportado estuvo formada por estudiantes universitarios cursantes de la asignatura ID1-113, la cual es la última de una serie de tres impartida por el Departamento de Idiomas de la Universidad Simón Bolívar para el programa del ciclo básico, y cuyo objetivo es proporcionar a los estudiantes diferentes herramientas para la lectura en idioma inglés y oportunidades de exposición a los textos que versan sobre ciencia. La investigación se llevó a cabo durante un trimestre intensivo y tuvo una duración de ocho horas semanales durante seis semanas, con un total de 48 horas de clase, lo cual es equivalente al período trimestral regular. Para la presente investigación se tomaron dos secciones de la materia ID1-113; una de ellas fue escogida aleatoriamente como grupo control y la otra como grupo experimental. Los estudiantes, tanto del grupo control como del grupo experimental, presentaron un pretest al inicio del curso y la misma prueba como postest al final del curso. Sólo se tomaron para el estudio los resultados obtenidos de las pruebas de aquellos estudiantes que presentaron tanto el pretest como el postest, para un total de 36 estudiantes (20 del grupo experimental y 16 del grupo control).
4.2 Materiales e instrumentos
La prueba utilizada tanto para el pretest como para el postest pertenece a la serie International English Language Testing System (IELTS), la cual está basada en la lectura de un texto de tipo argumentativo titulado "Population Viability Analysis" (ver Anexo) y cuyas preguntas evalúan la búsqueda de información específica, búsqueda de la idea principal y secundaria; identificación de opiniones y comprensión de paráfrasis. Además de la prueba de comprensión de lectura, se agregaron 10 grupos nominales complejos aislados extraídos del mismo texto, los cuales debían ser traducidos antes de comenzar la prueba de comprensión de lectura. La razón por la cual se le añadió una actividad con grupos nominales aislados fue la de observar si los estudiantes podían decodificar los grupos nominales complejos de manera aislada, y si, por el contrario, podían decodificarlos dentro de un texto para así contribuir a la comprensión del mismo. Durante el entrenamiento que tuvieron los estudiantes del grupo experimental trabajaron de estas dos diferentes formas, es decir, con grupos nominales de manera aislada y con grupos nominales dentro de una lectura de ciencia con preguntas de comprensión. Para el entrenamiento en la decodificación del grupo nominal complejo se utilizaron ejercicios de acuerdo con lo sugerido por Beke (2002), Bloor y Bloor (1995), Izquierdo y Bailey (1998), Jullian (2002), La Torre y Pons (1986) y Trimble (1985), quienes apuntan a la necesidad de establecer una práctica sistemática con grupos nominales complejos, la cual ya había sido utilizada durante el estudio preliminar (estudio piloto), realizado en un trimestre regular. El grupo experimental recibió como parte del tratamiento una serie de ejercicios clasificados en algunos de los siguientes renglones: 1) traducción de grupos nominales complejos del inglés al español y viceversa; 2) paráfrasis de grupos nominales complejos en inglés; 3) identificación de grupos nominales complejos en una lectura hecha en clase, 4) construcción de grupos nominales complejos a partir de palabras dadas, 5) identificación del núcleo del grupo nominal y del núcleo del grupo verbal, 6) identificación de diferencias de significado al alterar el orden de los elementos del grupo nominal.
En la primera semana del trimestre se aplicó la prueba, tanto en la sección experimental como en la sección de control. A partir de la segunda semana, la profesora de la asignatura reservó parte de las clases para la ejercitación del grupo nominal complejo, ejercitación que se realizó sólo con el grupo experimental. Al final de la sexta semana se aplicó como postest la misma prueba utilizada para el pretest. En esta ocasión, los estudiantes respondieron, además, dos preguntas que tenían como finalidad determinar su percepción en cuanto a sus conocimientos previos relativos al grupo nominal complejo en inglés y a la utilidad del tratamiento aplicado.
4.3 Análisis de los datos
Los datos incluyeron las respuestas dadas por los estudiantes a la prueba de comprensión de lectura, así como las traducciones de los 10 grupos nominales complejos tanto del pretest como del postest, a los cuales se aplicó un análisis estadístico de tipo descriptivo. Los criterios de corrección fueron los siguientes: Para la prueba de comprensión de lectura se utilizó la clave de respuestas incluida para las pruebas del English Language Testing System, adjudicando un punto por cada respuesta correcta y 0 para la incorrecta, para un total máximo de 12 puntos. Para la corrección de los 10 grupos nominales se siguieron los siguientes criterios: i) identificación correcta del núcleo del grupo; ii) identificación como grupo nominal y no como oración, y iii) relación correcta entre modificadores y núcleo. No se tomaron en cuenta los elementos lexicales tales como la traducción incorrecta de una palabra. Una vez corregidas las pruebas, las respuestas se codificaron en un sistema binario: i) 1 para una respuesta correcta, y ii) 0 para una respuesta incorrecta. Teniendo en cuenta el pre y postest, los cuales tenían 12 ítems cada uno, más la parte correspondiente a la traducción de 10 grupos nominales, se obtuvo un total de 1584 datos, que corresponden a la suma del total de respuestas dadas por ambos grupos en el pretest y en el postest.
5. RESULTADOS
El procesamiento de los datos revela una mejora de 11,25% de respuestas correctas globales (incluyen tanto la prueba de comprensión de lectura como la traducción de los grupos nominales) en el grupo experimental, frente a una mejora de 9,8% del grupo control, tal como se muestra en el cuadro 1.
Cuadro 1 Resultados globales en el área de comprensión de la lectura
| Grupo | % Respuestas Correctas | Mejora | |
| Pre | Post | ||
| Control | 59,9 | 69,79 | 9,89 |
| Experimental | 61,67 | 72,92 | 11,25 |
En los cuadros 2 y 3 se muestran por separado los resultados de la prueba de comprensión de lectura y de la traducción de grupos nominales aislados. Llama la atención que en la traducción de los grupos nominales el grupo experimental no tuviese variación de los resultados, mientras que el grupo control sí muestra una mejora. Este resultado es sorprendente e inesperado, por lo que se procedió primero a examinar los casos individuales, y luego a analizarlos con una perspectiva cualitativa, desde la cual se aprecian cambios interesantes que apuntan hacia la conveniencia del entrenamiento específico con el grupo nominal complejo para la comprensión de lectura en textos de ciencia.
Cuadro 2 Resultados globales en el pretest y postest del grupo experimental
| Experimental | Pretest | Postest | ||||||
| Respuestas | Compresion | Grupos Nominales | Compresión | Grupos Nominales | ||||
| f | % | f | % | f | % | f | % | |
| Correctas | 148 | 61,67 | 151 | 75,50 | 175 | 72,92 | 151 | 75,50 |
| incorrectas | 92 | 38,33 | 49 | 24,50 | 65 | 27,08 | 49 | 24,50 |
| Totales | 240 | 100.00 | 200 | 100,00 | 240 | 100,00 | 200 | 100,00 |
Cuadro 3 Resultados globales en el pretest y postest del grupo control
| Control | Pretest | Postest | ||||||
| Respuestas | Compresión |
| Grupos Nominales |
| Compresión |
| Grupos Nominales | |
| f | % | f | % | f | % | f | % | |
| Correctas | 115 | 59,90 | 103 | 64,38 | 134 | 69,79 | 124 | 77,50 |
| 77 | 40,10 | 57 | 35,63 | 58 | 30,21 | 36 | 22,50 | |
| 192 | 100,00 | 160 | 100,00 | 192 | 100,00 | 160 | 100,00 |
Al comparar las respuestas dadas por los estudiantes del grupo experimental en la prueba de lectura, podemos observar que no hay diferencias importantes entre el pre y postest. Con excepción de la pregunta nº 1, la cual fue notablemente mejor respondida en el postest, en el resto de las preguntas de la prueba (preguntas 2 a la 12) se observa que los estudiantes del grupo experimental respondieron de manera muy parecida al pretest. Sin embargo, se puede notar que obtuvieron una mejora en seis de las 12 preguntas y disminuyeron su desempeño sólo en cuatro (dos preguntas se mantuvieron iguales).

Además, dos de las preguntas en las que se aprecia mejora pertenecen a la parte C, la cual exige mayor capacidad de síntesis y comprensión de las ideas principales. Para responder las preguntas de las partes A, B y D el estudiante no tiene que escribir una respuesta, sino seleccionar la opción correcta de un número limitado de posibilidades. En cambio, la parte C (preguntas números 9, 10 y 11) de la prueba exige que el estudiante generalice y comprenda la paráfrasis para poder completar un enunciado que recoge una idea general del texto. Es significativo el hecho de que, para esta parte de la prueba, muchos estudiantes de ambos grupos ni siquiera hayan prestado atención a la instrucción que limita la respuesta de la sección C a un máximo de tres palabras (in no more than three words). La costumbre de responder ítems de selección, y la falta de atención a la forma de elaborar el examen podría haber ocasionado que los estudiantes del grupo experimental no hayan obtenido una mejora significativa en el postest.
Los gráficos 2 y 3 ilustran la mejora de cada estudiante, tanto del grupo control como del experimental en la prueba de comprensión de lectura. A pesar de la escasa mejora de 11,25% del grupo experimental, existe una mayor homogeneidad en el progreso individual (sólo dos estudiantes de este grupo obtienen variación negativa), la cual no parece ser atribuible a factores individuales. En el grupo control, por el contrario, cuatro individuos obtienen variación negativa.
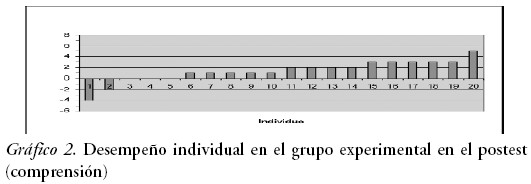

En el grupo experimental, tres individuos mantienen el mismo nivel, mientras que en el grupo control sólo dos se mantienen sin variación. Esto podría indicar que, a pesar de la poca mejora del grupo experimental, el tratamiento pudo haber contribuido a un mejor desempeño de una mayoría de estos estudiantes en el postest, aunque fuese de una o tres preguntas. A pesar de que el porcentaje de mejora es escaso, se puede notar que 15 individuos del grupo experimental mejoraron en la prueba de comprensión de lectura, es decir un 75% de los individuos obtiene entre una y cinco preguntas correctas de más en el postest. En cambio, en el grupo control sólo un 62% de los estudiantes mejora aumentando entre uno y siete el número de respuestas correctas.
6. DISCUSIÓN
Aunque los resultados muestran que el grupo experimental tuvo una leve mejora en la prueba de lectura, y una ausencia de mejora en la traducción de los grupos nominales aislados, se podría afirmar que en el postest del grupo experimental hubo una ganancia de información en la decodificación de los grupos nominales, lo cual se aprecia no sólo en la prueba de comprensión lectora, sino también en la traducción de grupos nominales aislados. Mientras que en el pretest algunos estudiantes del grupo experimental tradujeron los grupos nominales como estructura SVO (lo cual revela una incapacidad para reconocer las estructuras y para reconocer una forma -ing como modificador), en el postest sólo ocurrieron cuatro casos de este tipo de error, lo cual puede indicar una mejor noción del grupo nominal y sus constituyentes, a pesar de no haber alcanzado la respuesta correcta. Por ejemplo, un estudiante del grupo experimental en el pretest traduce el grupo a species that occurs in five isolated places each containing 20 individuals, de la siguiente forma: una especie que ocurre en cinco lugares separados contiene 20 individuos, como una oración. Sin embargo, en el postest lo traduce como una especie que ocurre en cinco lugares dispersos, cada uno con 20 individuos. Esta última respuesta parece indicar que hay un esfuerzo por traducirlo como una frase, y no como una oración, lo cual constituye un cambio significativo.
En cuanto a la prueba de comprensión de lectura, y especialmente en aquella sección que exige mayor capacidad de síntesis (parte C), se puede apreciar una mayor recuperación de información y mejor comprensión de los fenómenos presentados en el texto por parte de los estudiantes del grupo experimental, a pesar del hecho de que algunos ítems no hayan sido respondidos de manera correcta. Un ejemplo de esta afirmación se puede encontrar en algunas de las respuestas dadas en el postest a la siguiente pregunta de completación:
While the population of a species may be on the increase, there is always a chance that small isolated groups ________________________.
El mismo estudiante que en el pretest completa el ítem con to extinct, en el postest lo completó con will not have the same probability to live, lo cual no sólo revela mayor comprensión del texto, sino una forma sintáctica compleja y correcta. Mientras que al responder con to extinct, el estudiante afirma que se extinguirá la especie, en el postest parece comprender que no necesariamente se extinguirá la especie, sino que tendrá más probabilidades de extinción.
A pesar de la poca mejora del grupo experimental, el análisis detallado de las respuestas mostró que después de haber sido sometidos al entrenamiento con el grupo nominal inglés, los estudiantes poseen una noción más clara del tipo de discurso que leen, el cual exige formas más complejas para expresar ideas más abstractas. Aunque muchas de las respuestas dadas por los estudiantes no constituyen la respuesta esperada, existe un cambio que indica que los estudiantes se aventuran a formas más complejas y precisas, tal como se observa en el análisis detallado de cada pregunta. Es posible que el cambio en algunas respuestas represente un desarrollo hacia la decodificación de mensajes más complejos y de formas de expresión más avanzadas, y que los errores pueden estar relacionados con diferentes períodos o facetas del desarrollo de habilidades de acuerdo con Bernhardt (1991).
Es también probable que el conocimiento de las estructuras de grupos nominales muy diferentes al español (tal como sustantivos premodificando otros sustantivos) necesite más tiempo y práctica para su consolidación. Por otra parte, el tratamiento aplicado al grupo experimental reveló que el desempeño de los estudiantes era superior en tareas específicas, como la identificación del núcleo. En cambio, al enfrentarse a tareas de mayor dimensión y complejidad, los estudiantes parecen desviar su atención de los elementos específicos hacia las respuestas a una prueba o hacia la comprensión de lectura. Es posible preguntarse si la enseñanza explícita de un rasgo sintáctico hace que el lector centre su atención en dicho aspecto de manera exagerada, en detrimento de otros factores implicados en la lectura, como por ejemplo identificar la idea principal de un párrafo. La lectura implica una interacción entre muchos factores y, por consiguiente, no es posible hacer hincapié en un solo elemento para atribuirle la responsabilidad por el fracaso o éxito de la comprensión, tal como lo expresa Bernhardt (1991: 162): "El análisis de los protocolos de los estudiantes demuestra más allá de toda duda que varios elementos provenientes del texto y provenientes del conocimiento del lector interactúan entre sí para desarrollar la comprensión".4 Existen otros factores implicados en el desarrollo de la comprensión de lectura en inglés que indican que hay una cantidad de variables lingüísticas y no lingüísticas que pueden influir negativamente en la comprensión.
7. CONCLUSIONES
De lo observado durante la investigación, aunque no puede conducir a afirmaciones contundentes, se pueden establecer las siguientes consideraciones generales:
1. El grupo nominal complejo tiene una notable presencia en el discurso científico y su correcta decodificación contribuye al mejoramiento de la comprensión de la lectura de este tipo de discurso.
2. Los estudiantes parecen estar orientados a resolver tareas específicas. Esto se evidencia en el hecho de que en los ejercicios del tipo de identificación del núcleo del grupo nominal, lo hacen de manera satisfactoria. Sin embargo, enfrentados a tareas más complejas, no parecen transferir las destrezas aprendidas y el uso queda circunscrito a un ejercicio. Es posible que en el proceso de lectura utilicen su capacidad cognitiva en el área léxica, y sólo en segundo lugar los sintácticos, tal como afirma Van Patten (2002).
3. Según lo observado en la investigación, los grupos nominales complejos similares a los del español no presentan dificultad para la decodificación. En cambio, aquellos marcadamente diferentes, tales como uno o más sustantivos modificando a un núcleo, sí constituyen un punto de dificultad, aún más si se considera que este tipo de estructura puede a su vez ocurrir dentro de otras, haciendo más ardua la tarea de decodificar.
4. Al responder las preguntas de percepción al final del trimestre, los estudiantes afirmaron en un cien por ciento que lo aprendido había sido de utilidad en la lectura. Muchos de ellos no conocían la manera de decodificar el grupo nominal complejo en inglés, tal como demostró el porcentaje de respuesta: sólo un 38,89% dijo conocer la estructura del grupo nominal inglés, frente a un 61,11% que respondió no conocerla.
5. El trimestre podría ser un período de tiempo corto para el aprendizaje del grupo nominal y tal como afirma Lemke (2003), requiera de un período más largo. Asimismo, existe la posibilidad de que el resultado favorable pueda observarse a más largo plazo y no inmediatamente después del entrenamiento.
6. Todavía queda por establecerse el momento adecuado durante el desarro- llo de la adquisición de una lengua extranjera para la enseñanza de rasgos complejos tales como la sintaxis. Este es un punto controversial que constituye un campo fructífero para futuras investigaciones.
La enseñanza del grupo nominal complejo en inglés es importante, pues éste constituye una estructura fundamental del discurso científico y por sus marcadas diferencias con el grupo nominal en español; y aunque el estudio reportado deja interrogantes, nos permite reflexionar sobre elementos importantes en la enseñanza de inglés con fines académicos y podría constituir la base de hipótesis para futuras investigaciones.
REFERENCIAS BIBLIOGRÁFICAS
1. Albentosa, J. y Moya, A. (2000). La reducción del grado de transitividad de la oración en el discurso científico en lengua inglesa. Revista Española de Lingüística, 30(1), 445-468) [Artículo en línea]. Disponible: http://dialnet.unirioja.es/servlet/articulo?codigo=41384 [Consulta: 2002, mayo 12] [ Links ]
2. Beke, R. (2002). Introducción a la lectura en inglés (Cuadernos de Postgrado No. 30). Caracas: Universidad Central de Venezuela. [ Links ]
3. Bernhardt, E. (1991). Reading development in a second language. Theoretical, empirical and classroom perspective. New Jersey: Ablex Publishing. [ Links ]
4. Bialystok, E. (1990). Communication strategies. A psychological analysis of second language use. Oxford: Basil Blackwell. [ Links ]
5. Bloor, T. y Bloor, M. (1995). The functional analysis of English. Londres: Edward Arnold. [ Links ]
6. Colombi, M. C. (2002). El desarrollo del registro académico del español en estudiantes latinos en EE. UU. [Documento en línea]. Ponencia presentada en el II Congreso Internacional de la Lengua Española, Valladolid. Disponible: http://cvc.cervantes.es/obref/congresos/valladolid/ponencias/unidad_diversidad_del_espanol/3_el_espanol_en_los_EEUU/colombi_m.htm [Consulta: 2002, diciembre 5] [ Links ]
7. Halliday, M. y Martin, J. R. (1993). Writing science: Literacy and discursive power. Londres: Falmer Press. [ Links ]
8. Hamilton-Toovey, S. y Mateluna, M. (2000-2001). La traducción al español de los nominales complejos del inglés. Boletín de Filología, t. XXXVIII, 128-166. [ Links ]
9. Hernanz, M. L. y Brucart, J. M. (1987). La sintaxis. Barcelona: Editorial Crítica. [ Links ]
10. Izquierdo, B. y Bailey, D. (1998). Complex noun phrases and complex nominals: Some practical considerations. TESL Reporter, 31(3), 19-29. [ Links ]
11. Jakeman, V. y McDowell, C. (1995). International English Language Testing System (IELTS). Cambridge: Cambridge University Press. [ Links ]
12. Jullian, P. (2002). Uncovering implicit information in original compounds. ELT Journal, 56(4), 359-367. [ Links ]
13. Latorre, G. y Pons, H. (1986). Pedagogic models of the English complex noun phrase: A comparison between registers. En P. Wilcox (Comp.), ESP in practice (pp. 99-108). Washington, D. C.: United States Information Agency, English Language Programs Division. [ Links ]
14. Lemke, J. (1997, octubre 29). Nominalizations [Discusión en línea]. Disponible: http://www.isfla.org/Systemics/Contact/index.html[Consulta: 2003, agosto 29] [ Links ]
15. Myers, G. (1992). Textbooks and the sociology of scientific knowledge. English for Specific Purposes, 11, 3-17. [ Links ]
16. Nuttall, C. (1982). Teaching reading skills in a foreign language. Londres: Heinemann. [ Links ]
17. Quirk, R. (1972). A grammar of contemporary English. Londres: Longman. [ Links ]
18. Schnepf, A. y Schnöckel, H. (2002). Metalloid aluminum and gallium clusters: Element modifications on the molecular scale? Angewandte Chemie International Edition, 41(19), 3.532-3.554. [ Links ]
19. Trimble, L. (1985). English for science and technology: A discourse approach. Cambridge: Cambridge University Press. [ Links ]
20. van Dijk, T. y Kintsch, W. (1983). Strategies of discourse comprehension. Nueva York: Academic Press. [ Links ]
21. Van Patten, B. (2002). Processing attention: An update. Language Learning, 52(4), 755 803. [ Links ]
22. Ventola, E. (1996). Packing and unpacking of information in academictexts. En E. Ventola y A. Mauranen (Comps.), Academic writing. Intercultural and textual issues (pp. 153-194). Amsterdam: John Benjamins. [ Links ]
MARTA TRÍAS
Es Licenciada en Idiomas Modernos de la Universidad Central de Venezuela y Magíster en Inglés como Lengua Extranjera de la UCV. Actualmente es profesora de inglés y de español como lengua extranjera, adscrita al Departamento de Idiomas de la Universidad Simón Bolívar. Entre sus intereses académicos y de investigación están la sintaxis, la lingüística funcional sistémica y la escritura académica.
Notas
1 unpack
2 Mi traducción. Original: "Learners who are in the process of explicating and organizing linguistic knowledge may benefit from forms of instruction which present rules and structures as organizing principles."
3 Mi traducción. Original: " it is only with long practice in relatively specific contexts of use that people come to be more naturally at home in the highly nominalized style."
4 Mi traducción. Original: "The analysis of the students recalls demonstrates beyond a doubt that various text driven and knowledge-driven elements interact with each other to develop an understanding."